
FXの値動きをAIで分類(BUY・SELL・HOLD など)するとき、
「過去何本のデータをモデルに入力すれば一番うまく予測できるのか?」
という疑問は、誰もが一度は考えます。
今回は、実際にシーケンス長(過去データの本数)を変えながら、
F1 Macro(クラスの平均的な予測精度) がどのように変化するか調べてみました。
シーケンス長とは?
AIモデルに入力する「過去データの長さ」です。
- 10 → 過去10本のローソク足を参照
- 50 → 過去50本のローソク足を参照
- 100 → 過去100本のローソク足を参照
長くすると「より多くの情報」が入りますが、
その分だけノイズも増えるため、精度が下がることもあります。
実験の条件
- タスク:Catboost分類(BUY/SELL)
- 評価指標:F1 Macro
- シーケンス長の候補:5〜100(5刻み)
- M5,M15,H1,D1のOHLCやテクニカルの変化率
- 目的変数は1,2,3,6,12時間後の変化率
AIが使う特徴量やモデル構造は同じで、
シーケンス長だけを変えて比較しました。
■ 実験結果(グラフ)
下のグラフが今回の結果です。
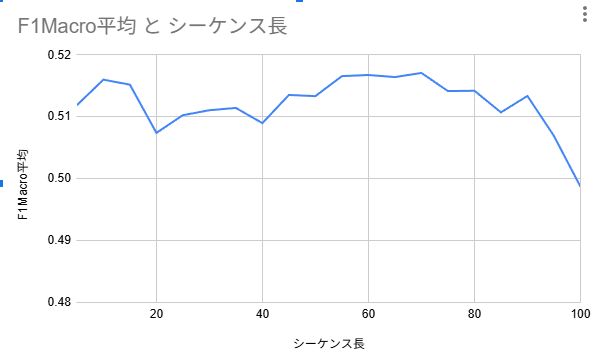
縦軸:F1 Macro 平均
横軸:シーケンス長
結果のまとめ
50〜70本付近がもっとも安定して高い
グラフを見ると…
- 50
- 60
- 70
このあたりで F1 Macro ≈ 0.52 と、最も高い値になりました。
つまり、
短すぎると情報が足りず、
長すぎるとノイズが増えてしまう。
その中間が一番うまくいく。
という、直感的にも納得しやすい結果でした。
なぜ長すぎると精度が落ちるのか?
シーケンスが長くなるほど、モデルは…
- 古い情報に引っ張られる
- 今の値動きに合わないデータが混ざる
- ノイズ(予測に役立たない揺れ)が増える
といった問題が起きやすくなります。
FXはとくに
短期ほどランダムノイズが多く、
長期ほど“相場状態が変わってしまう”
ため、「中間の長さ」を選ぶことが重要になります。
シーケンス長の実用的な指針
今回の実験結果から、分類モデルにおいては…
✔ 50〜70本
もっとも安定して高い精度
✔ 30〜40本
そこそこ良い。
軽量モデルを作りたいときに適切。
✔ 100本以上
情報が多すぎて逆に精度が下がりやすい。
という傾向が見られました。
まとめ
今回の検証では、
FXの分類タスクでは、シーケンス長は50〜70本が最適
という結果になりました。
もちろん、使う特徴量・モデル・通貨ペアによって変わるため、
あなたの環境でもぜひ同じように比較してみることをおすすめします。
この記事が、FXのAIモデル設計の参考になればうれしいです。
オンラインコミュニティ
こちらのコミュニティで、AIや機械学習をトレードに活かすために日々探求しています。
興味のある方は覗いてみてください。