本記事では、最新のAI技術を活用した2つの予測手法、回帰モデルと分類モデルを徹底比較します。それぞれの特徴、実装方法、そしてMQL5を用いたONNXモデルの統合テクニックまで、詳しく解説します。
さらに、両モデルを組み合わせたアンサンブル手法による予測力向上の可能性も探ります。記事の概要は下記の通りです。
- 回帰モデルと分類モデルの基本と違い
- MQL5でのAIモデル実装手順
- アンサンブル手法による予測精度の向上
- 実践的なFX取引への応用方法
分類・回帰どっちがいいの??
価格予測モデルの基礎
価格予測モデルは、過去のデータを基に将来の価格や価格変動を予測することを目的としています。ここでは、回帰モデルと分類モデルという2つの異なるアプローチを紹介します。
回帰モデルの特徴と実装
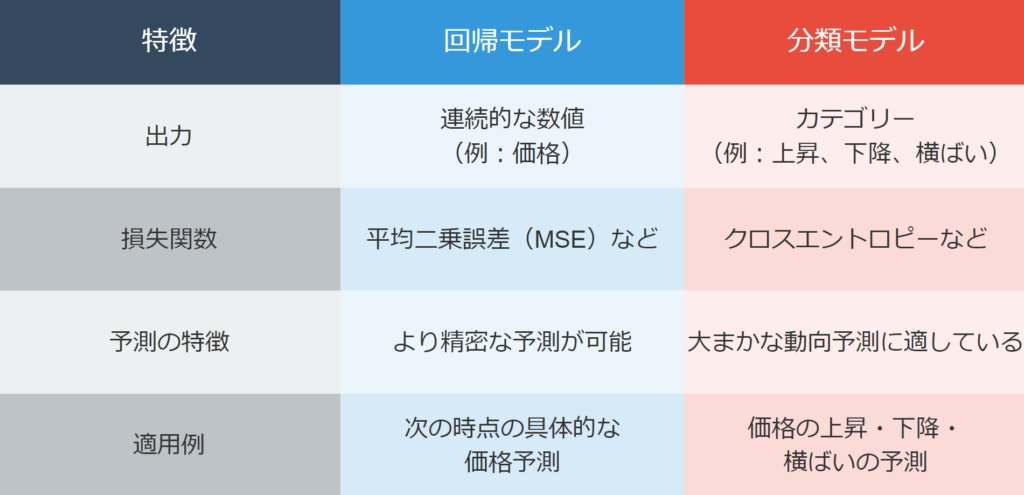
回帰モデルは、連続的な数値を予測するのに適したモデルです。FX取引における回帰モデルは、次の時点の具体的な価格を予測することを目的としています。
回帰モデルの主な特徴:
- 出力が連続的な数値(例:明日の終値)
- 損失関数として平均二乗誤差(MSE)などを使用
- より精密な予測が可能だが、急激な価格変動に弱い場合がある
def collect_dataset(df: pd.DataFrame, history_size: int):
n = len(df)
xs = []
ys = []
for i in tqdm(range(n - history_size)):
w = df.iloc[i: i + history_size + 1]
x = w[['open', 'high', 'low', 'close']].iloc[:-1].values
y = w.iloc[-1]['close']
xs.append(x)
ys.append(y)
X = np.array(xs)
y = np.array(ys)
return X, y
# データの正規化
m = X.mean(axis=1, keepdims=True)
s = X.std(axis=1, keepdims=True)
X_norm = (X - m) / s
y_norm = (y - m[:, 0, 3]) / s[:, 0, 3]回帰モデルの実装では、過去の価格データ(例:過去10日間のOHLC価格)を入力として使用し、次の日の終値を予測します。このプロセスでは、データの正規化が重要な役割を果たします。価格データを平均0、標準偏差1に正規化することで、モデルの学習効率が向上し、より安定した予測が可能になります。
分類モデルの構造と学習方法
分類モデルは、予測結果をカテゴリーに分類するモデルです。FX取引における分類モデルは、価格の上昇、下降、横ばいといったカテゴリーを予測します。
分類モデルの主な特徴:
- 出力がカテゴリー(例:価格上昇、価格下降、変化なし)
- 損失関数としてクロスエントロピーなどを使用
- 大まかな価格動向の予測に適しているが、具体的な価格値は提供しない
def collect_dataset(df: pd.DataFrame, history_size: int):
n = len(df)
xs = []
ys = []
for i in tqdm(range(n - history_size)):
w = df.iloc[i: i + history_size + 1]
x = w[['close']].iloc[:-1].values
delta = x[-1] - w.iloc[-1]['close']
if np.abs(delta) <= 0.0001:
y = 0, 1, 0
elif delta < 0:
y = 1, 0, 0
else:
y = 0, 0, 1
xs.append(x)
ys.append(y)
X = np.array(xs)
Y = np.array(ys)
return X, Y
# データの正規化
m = X.mean(axis=1, keepdims=True)
s = X.std(axis=1, keepdims=True)
X_norm = (X - m) / s分類モデルの実装では、過去の価格データ(例:過去63日間の終値)を入力として使用し、次の日の価格変動カテゴリーを予測します。このモデルでも、データの正規化が重要です。また、出力層にはソフトマックス関数を使用し、各カテゴリーの確率を得ることが一般的です。
2クラス(1ラベル)分類の場合は、シグモイドだねぇ
MQL5を用いたONNXモデルの実装
回帰モデルのMQL5での実装手順
回帰モデルをMQL5で実装する際の主要なステップは以下の通りです:
- ONNXモデルの読み込み:MQL5のOnnxCreateFromBuffer関数を使用して、事前に学習されたモデルを読み込みます。
- 入力データの準備:過去10日間のOHLC価格データを取得し、正規化します。これには、MQL5の行列演算機能を活用します。
- モデルの実行:OnnxRun関数を使用して、準備した入力データでモデルを実行します。
- 結果の解釈:モデルの出力を逆正規化して実際の価格に変換し、現在の価格と比較して上昇、下降、横ばいのいずれかに分類します。
int PredictPrice(const long handle, const int sample_size)
{
static matrixf input_data(sample_size,4);
static vectorf output_data(1);
static matrix mm(sample_size,4);
static matrix ms(sample_size,4);
static matrix x_norm(sample_size,4);
matrix rates;
if(!rates.CopyRates(_Symbol,_Period,COPY_RATES_OHLC,1,sample_size))
return(-1);
vector m=rates.Mean(1);
vector s=rates.Std(1);
for(int i=0; i<sample_size; i++)
{
mm.Row(m,i);
ms.Row(s,i);
}
x_norm=rates.Transpose();
x_norm-=mm;
x_norm/=ms;
input_data.Assign(x_norm);
if(!OnnxRun(handle,ONNX_NO_CONVERSION,input_data,output_data))
return(-1);
double predicted=output_data[0]*s[3]+m[3];
int predicted_class=-1;
double delta=rates[3][sample_size-1]-predicted;
if(fabs(delta)<=0.0001)
predicted_class=PRICE_SAME;
else if(delta<0)
predicted_class=PRICE_UP;
else
predicted_class=PRICE_DOWN;
return(predicted_class);
}日次データを使用していますが、より短い時間枠でモデルを訓練し実行することも可能です。ただし、そのような場合はモデルの再訓練が必要になる可能性があります。

分類モデルのMQL5への統合方法
分類モデルのMQL5への統合は、回帰モデルと類似していますが、いくつかの重要な違いがあります:
- ONNXモデルの読み込み:回帰モデルと同様にOnnxCreateFromBuffer関数を使用します。
- 入力データの準備:過去63日間の終値データを取得し、正規化します。ここでは、ベクトル演算を使用してデータを処理します。
- モデルの実行:OnnxRun関数を使用してモデルを実行します。
- 結果の解釈:モデルの出力は3つのカテゴリー(上昇、下降、横ばい)の確率分布になります。最も確率の高いカテゴリーを選択します。
int PredictPriceMovement(const long handle, const int sample_size)
{
static vectorf input_data(sample_size);
static vectorf output_data(3);
if(!input_data.CopyRates(_Symbol,_Period,COPY_RATES_CLOSE,1,sample_size))
return(-1);
float m=input_data.Mean();
float s=input_data.Std();
input_data-=m;
input_data/=s;
if(!OnnxRun(handle,ONNX_NO_CONVERSION,input_data,output_data))
return(-1);
return(int(output_data.ArgMax()));
}分類モデルの利点は、直接的に取引シグナル(買い、売り、保留)に変換しやすいことです。ただし、価格変動の大きさに関する情報は提供されないため、リスク管理には追加の戦略が必要になる場合があります。
モデル評価とパフォーマンス分析
モデルの実装後、その性能を評価することが重要です。ここでは、単一モデルの評価とアンサンブル手法による改善について説明します。
単一モデルの予測精度
回帰モデルと分類モデルの予測精度を評価する際は、異なる指標を使用します:
回帰モデルの評価指標:
- 平均二乗誤差(MSE)
- 平均絶対誤差(MAE)
- R2スコア
分類モデルの評価指標:
- 精度(Accuracy)
- 適合率(Precision)
- 再現率(Recall)
- F1スコア
これらの指標を使用して、各モデルの性能を評価し、比較することができます。ただし、FX取引における真の指標は、実際の取引結果(利益/損失)であることを忘れないでください。
アンサンブル手法による予測力の向上
アンサンブル手法は、複数のモデルを組み合わせてより強力な予測を行う方法です。本記事で紹介した回帰モデルと分類モデルを組み合わせることで、予測精度を向上させることができます。
アンサンブルの例:
- 両モデルが同じ方向(上昇または下降)を予測した場合のみ取引を行う
- 回帰モデルの予測価格変動の大きさと分類モデルの確率を組み合わせて、取引サイズを決定する
- 分類モデルで方向を決め、回帰モデルで利益確定/損切りレベルを設定する
void Predict(void)
{
ExtPredictedClass1 = PredictPrice(ExtHandle1, SAMPLE_SIZE1);
ExtPredictedClass2 = PredictPriceMovement(ExtHandle2, SAMPLE_SIZE2);
if(ExtPredictedClass1 == ExtPredictedClass2)
ExtPredictedClass = ExtPredictedClass1;
else
ExtPredictedClass = -1;
}アンサンブル手法を使用することで、各モデルの長所を活かしつつ、短所を補完することができます。
まとめ
FX取引戦略への組み込み方
機械学習モデルをFX取引戦略に組み込む際の考慮点:
- リスク管理:モデルの予測だけでなく、適切なポジションサイジングとストップロスの設定が重要です。
- 取引コスト:スプレッドやスワップポイントなどの取引コストをモデルに組み込むことで、より現実的な戦略を構築できます。
- 市場状況の考慮:トレンド相場やレンジ相場など、異なる市場状況に応じてモデルの重みを調整することを検討します。
- 複数通貨ペアへの適用:単一の通貨ペアだけでなく、複数の通貨ペアにモデルを適用し、分散投資の効果を得ることができます。
- 定期的な再訓練:市場環境の変化に対応するため、定期的にモデルを再訓練することが重要です。
モデル改善の可能性と課題
FX予測モデルの改善に向けた今後の課題と可能性:
- より高度なモデルアーキテクチャ:LSTMやTransformerなどの時系列データに特化したモデルの導入を検討します。
- マルチタイムフレーム分析:異なる時間枠のデータを組み合わせることで、より包括的な予測が可能になる可能性があります。
- センチメント分析の統合:ニュースや社会メディアのデータを取り入れることで、市場センチメントを考慮した予測ができるかもしれません。
- 強化学習の適用:市場環境の変化に動的に適応できる強化学習モデルの開発が期待されています。
- 解釈可能性の向上:ブラックボックス化しがちな機械学習モデルの判断過程を、より解釈可能にする技術の開発が求められています。
FX市場における機械学習モデルの応用は、まだ発展途上の分野です。技術の進歩と共に、より精度の高い、そして実用的な予測モデルの開発が期待されています。
併用するのが良いという記事でした!
そりゃそうか!w
オンラインコミュニティ
こちらのコミュニティで、AIや機械学習をトレードに活かすために日々探求しています。
興味のある方は覗いてみてください。
参考記事
