 MQL5記事
MQL5記事 【MQL5】機械学習で勝つためのラベリングとは
この記事では、機械学習モデルにとって最も重要な工程の1つである「ラベリング」 について、実戦に即した考え方と具体的な手法をわかりやすく解説します。はじめに — なぜラベリングが重要なのか?一般的な機械学習では「価格がX日後に上か下か」をラベ...
MQL5記事 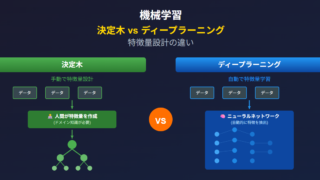 AI
AI  AI
AI 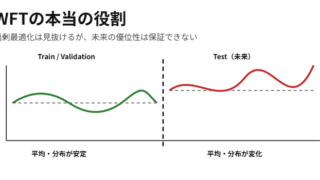 AI
AI  AI
AI  AI
AI  AI
AI  AI
AI 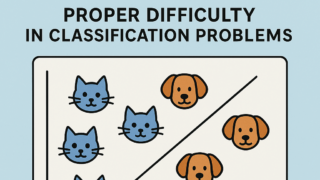 AI
AI  初心者向け
初心者向け