
ランダムフォレスト法は、機械学習の分野で高い評価を得ている予測モデルです。この記事では、ランダムフォレスト法の基本から、MQLでの実装、そしてFX自動売買システムへの応用まで、段階的に解説します。以下の内容をカバーしています:
- ランダムフォレスト法の歴史と基本概念
- Pythonを使用したモデルの作成と前処理
- ONNXフォーマットへの変換とMQL5での利用
- MetaTrader 5でのバックテストと性能評価
FXトレーダーやアルゴリズム開発者にとって、この記事は機械学習を取り入れた高度な取引戦略の構築への第一歩となるでしょう。
決定木で最も人気が高いモデルとも言っても過言ではないよ!
ランダムフォレストの基本と応用
ランダムフォレストは、機械学習の分野で広く使用される強力な予測モデルです。この手法は、複数の決定木を組み合わせることで、より正確で安定した予測を行います。
決定木からランダムフォレストへ
決定木は、データの特徴に基づいて分岐を繰り返し、最終的な予測を行う単純な構造です。しかし、単一の決定木は過学習しやすく、新しいデータに対する予測精度が低下することがあります。
ランダムフォレスト法は、この問題を解決するために考案されました。複数の決定木を「森」のように組み合わせることで、個々の木の弱点を補い合い、より強力な予測モデルを作り出します。
まさに木を見て森を見ずとはこのこと?
バギングとランダム性の導入
1990年代後半、統計学者のレオ・ブレイマンはバギング(ブートストラップ集約)という手法を提案しました。これは、元のデータセットから複数のサブサンプルを作成し、それぞれに対して個別のモデルを訓練する方法です。
2001年、ブレイマンはこの考えをさらに発展させ、ランダムフォレスト法を考案しました。この手法では、バギングに加えて、各決定木の構築時に特徴量をランダムに選択するという工夫が加えられています。これにより、個々の木の多様性が高まり、モデル全体の予測精度が向上します。
バギングってのは、複数の決定木を作成して多数決で最終判定する手法の一種
ランダムフォレスト法の利点
- 高い予測精度:複数のモデルの予測を組み合わせることで、単一モデルよりも高い精度を実現します。
- 過学習への耐性:ランダム性の導入により、個々の木が特定のデータに過度に適合することを防ぎます。
- 特徴量の重要度評価:モデルが各特徴量の重要度を評価できるため、データの理解が深まります。
- 大規模データセットへの適用可能性:並列処理が可能なため、大規模なデータセットにも効率的に適用できます。
- 異常値に対する堅牢性:複数のモデルを使用するため、異常値の影響を軽減できます。
これらの利点により、ランダムフォレスト法は金融、医療、マーケティングなど、さまざまな分野で活用されています。
基本的なRFモデルの作成
必要なライブラリのインストールとインポート
ランダムフォレストモデルを作成するには、まず必要なPythonライブラリをインストールし、インポートする必要があります。主に使用するライブラリは、scikit-learn、pandas、numpy、そしてONNX関連のライブラリです。
pip install onnx skl2onnx MetaTrader5
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestRegressor
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import RobustScaler, MinMaxScaler, PolynomialFeatures
import MetaTrader5 as mt5ライブラリの役割
- scikit-learn:機械学習モデルの構築と評価に使用します。
- pandas:データの操作と分析を行います。
- numpy:数値計算を効率的に行います。
- ONNX関連ライブラリ:モデルを異なるフレームワーク間で交換可能な形式に変換します。
これらのライブラリを組み合わせることで、データの前処理からモデルの訓練、評価、そして最終的なエクスポートまでの一連のプロセスを効率的に行うことができます。
機械学習やAIを作るならPythonから逃げてはいけない(‘Д’)
何もPythonの専門家になれとは言ってないから大丈夫
データの読み込みと処理
モデル作成の次のステップは、データの読み込みと処理です。この例では、MT5から価格データを取得し、終値のみを使用します。
mt5.initialize()
data = pd.DataFrame(mt5.copy_rates_range(SYMBOL, TIMEFRAME, START_DATE, STOP_DATE))
data['time'] = pd.to_datetime(data['time'], unit='s')
data.set_index('time', inplace=True)
data = data[['close']]データの準備
- MT5からの価格データ取得:特定の通貨ペア(例:EURUSD)の1時間足のデータを取得します。
- データのクリーニング:欠損値や異常値を除去し、データを成形します。
- 特徴量の選択:この例では終値のみを使用しますが、実際の応用では他の価格データ(始値、高値、安値)や出来高、さらには他の指標を特徴量として追加することも考えられます。
- データの分割:データを訓練セットとテストセットに分けます。一般的には、70-80%を訓練用、残りをテスト用に使用します。
データ前処理用のパイプラインの作成
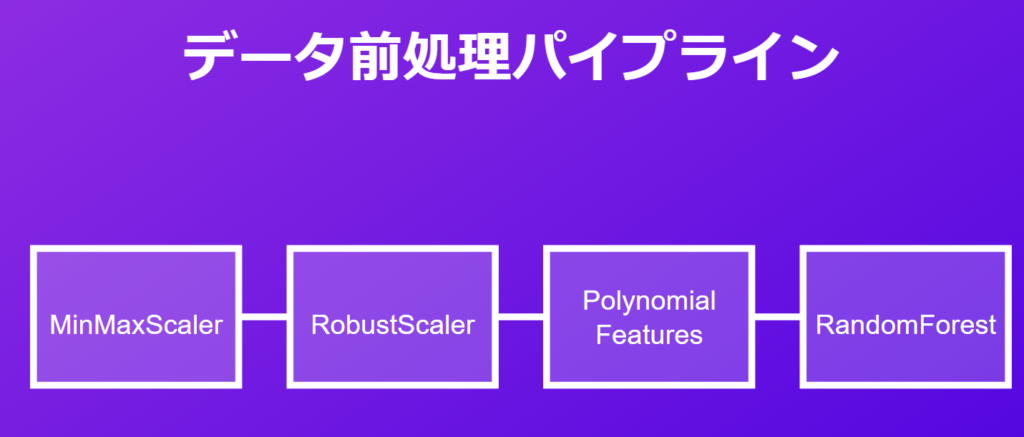
パイプラインの構成要素
scikit-learnのパイプライン機能を使用することで、データ前処理とモデル訓練を一連の流れとして扱うことができます。
pipeline = Pipeline([
('MinMaxScaler', MinMaxScaler()),
('robust', RobustScaler()),
('poly', PolynomialFeatures()),
('rf', RandomForestRegressor(n_estimators=20, max_depth=20))
])MinMaxScaler
MinMaxScalerは、データを0から1の範囲にスケーリングします。これにより、異なるスケールの特徴量を同じ範囲に収めることができます。金融データの場合、異なる通貨ペアや時期によって価格のスケールが大きく異なる可能性があるため、このステップは重要です。
RobustScaler
RobustScalerは、中央値と四分位範囲を使用してスケーリングを行います。これにより、外れ値の影響を軽減できます。金融市場では突発的なイベントによる急激な価格変動が起こることがあるため、このスケーラーは特に有用です。
PolynomialFeatures
PolynomialFeaturesは、非線形関係を捉えるための多項式特徴量を生成します。これにより、モデルがより複雑なパターンを学習できるようになります。金融市場の動きは往々にして非線形であるため、この処理は予測精度の向上に貢献する可能性があります。
RandomForestRegressor
最後に、ランダムフォレストモデル本体を設定します。ここでは、木の数や深さなどのハイパーパラメータを調整できます。これらのパラメータの最適な値は、データの性質や予測タスクによって異なるため、グリッドサーチなどの手法を用いて最適化することが一般的です。
パイプラインの訓練と評価
構築したパイプラインを使用して、モデルを訓練します。訓練後、テストデータを使用してモデルの性能を評価します。評価指標としてR2スコアを使用し、モデルの予測精度を確認します。
pipeline.fit(x_train, y_train)
predictions = pipeline.predict(x_test)
r2 = r2_score(y_test, predictions)
print(f'R2 score: {r2}')R2スコアの解釈
R2スコアは0から1の範囲を取り、1に近いほどモデルの予測精度が高いことを示します。例えば、R2スコアが0.7の場合、モデルがデータの変動の70%を説明できていることを意味します。ただし、金融市場の予測タスクでは、完璧な予測は不可能であり、比較的低いR2スコアでも実用的な価値がある場合があります。
予測は目安。AIも完全ではなく簡単に間違うからね。
自信満々に間違えられても困るからね
大事なのは予測値にちゃんとピークがあることだと思ってる。
予測値が90%以上は頭打ちしてるといってもいいかな
モデルをONNXに書き出し
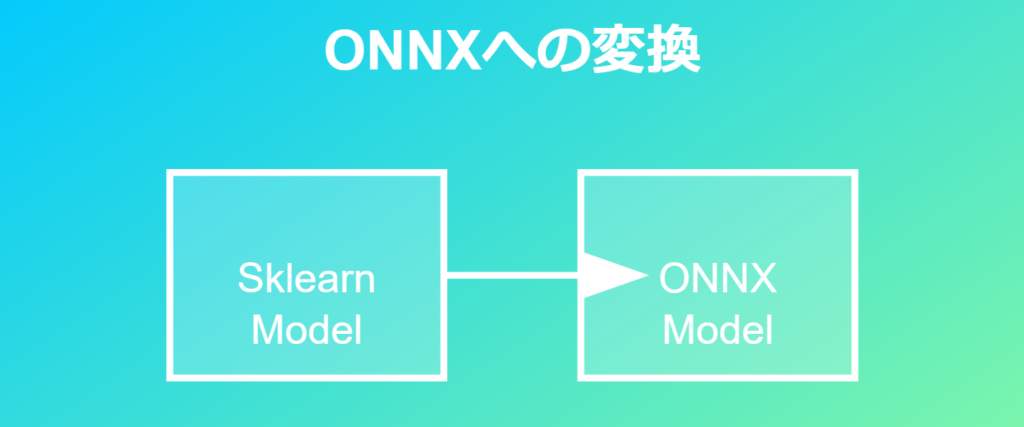
ONNXフォーマットへの変換
訓練したモデルは、ONNX(Open Neural Network Exchange)フォーマットに変換します。ONNXは異なる機械学習フレームワーク間でモデルを交換するための標準規格です。
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType
initial_type = [('float_input', FloatTensorType([None, n_features]))]
onnx_model = convert_sklearn(pipeline, initial_types=initial_type)ONNXの利点
- 相互運用性:異なるフレームワークやプラットフォーム間でモデルを共有できます。
- 最適化:ONNXランタイムを使用することで、モデルの推論速度を向上させることができます。
- 可視化:ONNXフォーマットのモデルは、専用のツールで視覚化できるため、モデルの構造を理解しやすくなります。
モデルの保存と移動
ONNXフォーマットに変換したモデルは、ファイルとして保存します。この例では、Googleドライブにモデルをアップロードしていますが、実際の使用環境に応じて適切な保存場所を選択してください。
import onnx
onnx.save_model(onnx_model, "rf_pipeline.onnx")ストラテジーテスターでモデルを確認する
EAの作成
MT5でONNXモデルを使用するには、専用のExpert Advisor(EA)を作成する必要があります。このEAは、ONNXモデルを読み込み、その予測に基づいて取引判断を行います。
#resource "Python/rf_pipeline.onnx" as uchar ExtModel[]
long ExtHandle = OnnxCreateFromBuffer(ExtModel, ONNX_DEFAULT);EAの主要コンポーネント
- モデルの読み込み:ONNXモデルをMT5環境に読み込みます。
- データの準備:現在の市場データをモデルの入力形式に変換します。
- 予測の実行:モデルを使用して価格の予測を行います。
- 取引ロジック:予測結果に基づいて、ポジションの開始、維持、終了を判断します。
- リスク管理:ストップロスやテイクプロフィットの設定など、リスク管理機能を実装します。
モデルのテストと結果
作成したEAをMT5のテスター機能を使用してバックテストします。テスト結果を分析し、モデルの実際の取引環境での性能を評価します。
バックテストの重要性
バックテストでは、過去のデータを使用してモデルの性能を評価します。これにより、モデルが実際の市場環境でどのように機能するかを推測できます。ただし、過去のパフォーマンスが将来の結果を保証するものではないことに注意が必要です。
必ずトレーニングに使用していない期間で評価しよう。
機械学習においてトレーニング期間で好成績は
ただの動作確認と同じくらい当然のことだよ
評価指標
- 総利益/損失:戦略の全体的な収益性を示します。
- 勝率:成功したトレードの割合を示します。
- プロフィットファクター:総利益を総損失で割った値で、戦略の効率性を示します。
- 最大ドローダウン:最大の損失幅を示し、リスク管理の重要な指標となります。
- シャープレシオ:リスク調整後のリターンを示す指標です。
これらの指標を総合的に評価し、モデルの性能を判断します。必要に応じてパラメータの調整や再学習を行い、モデルの改善を図ります。
まとめ

ランダムフォレスト法は、その高い予測精度と汎用性から、金融市場分析において強力なツールとなります。本記事では、Pythonでランダムフォレストモデルを作成し、ONNXフォーマットを介してMetaTrader 5で使用する方法を詳細に解説しました。
この手法を応用することで、より洗練された取引戦略の開発が可能になります。ただし、モデルの性能は使用するデータや設定に大きく依存するため、継続的な検証と改善が重要です。また、実際の取引では、以下の点に注意を払う必要があります:
- リスク管理:適切なポジションサイズとストップロスの設定が不可欠です。
- 市場環境の変化:モデルの定期的な再訓練と更新が必要です。
- オーバーフィッティングの回避:過去のデータに過度に適合しないよう注意が必要です。
- 取引コストの考慮:スプレッドや手数料を考慮した戦略の最適化が重要です。
- 複数の時間枠の分析:短期、中期、長期の傾向を総合的に判断することで、より堅牢な戦略を構築できます。
ランダムフォレスト法を含む機械学習モデルは、トレーダーにとって強力な分析ツールとなりますが、それらはあくまでも意思決定を支援するものであり、完全に自動化された取引システムの構築には慎重なアプローチが必要です。継続的な学習と改善を重ねることで、より堅牢で効果的な取引戦略を構築することができるでしょう。
オンラインコミュニティ
こちらのコミュニティで、AIや機械学習をトレードに活かすために日々探求しています。
興味のある方は覗いてみてください。
参考記事
記事本文のコードは、下記の記事の内容を引用しています。
