
この記事では機械学習で用いるONNXモデルの実行関数について説明します。使用する際に疑問になるところが多かったので覚書として作成した記事です。
関数の説明
bool OnnxRun(
long onnx_handle, // ONNXセッションハンドル
ulong flags, // 実行モードを説明するフラグ
... // モデルの入出力
);戻り値
true : 実行が成功
false : 実行が失敗
以下の場合実行が失敗します。
・無効なセッションハンドル
OnnxCreate関数で正しくハンドルを作成したかを確認してください。
・間違ったモデルの入出力
モデルの入出力形状を確認してください。
引数の説明
- long onnx_handle
ONNXセッションハンドル
OnnxCreate関数で作成した値を入力 - ulong flags
実行モードを説明するフラグ(ENUM_ONNX_FLAGS)
ONNX_DEBUG_LOGS:出力デバッグログを有効にします。これにより、モデルの実行中にデバッグ情報がログに出力されます
ONNX_NO_CONVERSION:自動変換を無効にし、ユーザーデータをそのまま使用します。これにより、入力データの型変換が行われず、そのままの形式でモデルに渡されますONNX_COMMON_FOLDER:Common\Filesフォルダからモデルファイルを読み込みます。このフラグの値はFILE_COMMONフラグと同じです
ONNX_DEFAULT:何も指定しない場合 - 型自動変換 モデルの入出力
モデルの入出力の形状はOnnxファイルに依存します。カンマ区切りで複数の出力結果を受け取ることができます。
フラグは「|(パイプ)」OR演算子で区切って複数指定できます。
重要な関数だからシッカリと(‘ω’)
モデル入出力の形状の確認
形状(シャープ)とは簡単に言うと入出力時の配列のサイズです。
基本的には1次元配列で入力しますが、LSTMなど時系列モデルでは2次元配列で入力することになります。
この形状がわからないとオニックスを使用して予測ができませんので、基本的にはOnInitでOnnxCreateで使用可能にしたときに、OnnxSetInputShape関数などで形状が正しいかどうかを確認します。
この形状はモデルを作成した人なら確認するまでもないです。なぜかというと入出力の形状を作成した本人ですから、、、
ともあれ入力形状を忘れることもありますので、確認する必要があります。
問い合わせる
作者に問い合わせるのが一番早いです。実際調べてもはっきりわかりません・・・(ポカーン)
関数で調べる
Onnxファイルの入出力情報を取得する関数を使用します。
- OnnxGetInputCount関数:ONNXモデルの入力数を取得します
- OnnxGetOutputCount関数:ONNXモデルの出力数を取得します
- OnnxGetInputName関数:インデックスによってモデルの入力の名前を取得します
- OnnxGetOutputName関数:インデックスによってモデルの出力の名前を取得します
- OnnxGetInputTypeInfo関数:モデルから入力型の説明を取得します
- OnnxGetOutputTypeInfo関数:モデルから出力型の説明を取得します
各関数の使用方法については割愛します。
工数が多いので非推奨。
ファイルを開いて確認
メタエディターでOnnxファイルを実際に開いて確認します。
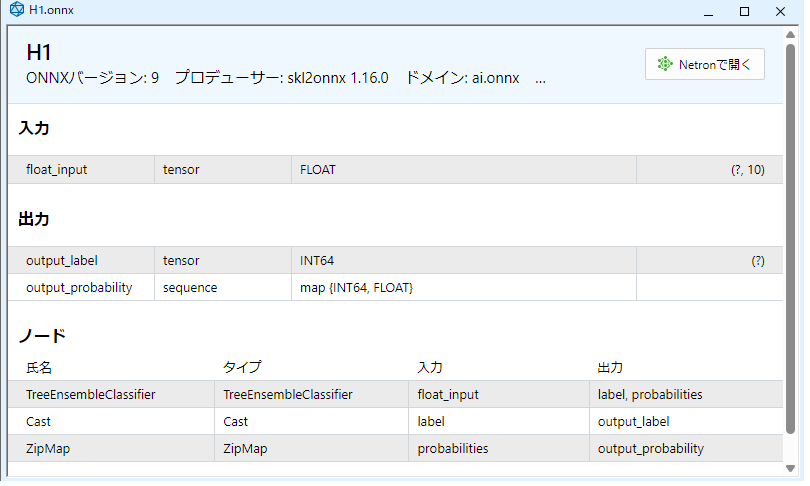
上記のOnnxファイルの見方について説明します。
入力
名前:float_inputという名前の1つの入力値があります。
データの形状:tensor(テンソル)、多次元配列であることが示されています。
データの型:FLOAT型の配列であることがわかります。機械学習では正確にはfloat型の配列はvecrorf、double型はvectorが使用されています。もちろんfloat型、double型で入力しても問題ないです(個人的にこちらがオススメ)。
データのサイズ:今回の場合は最初の数字が「?」不明。二つ目の数字が「10」となっています。調べたところ「?」部分が1次元目のサイズ、10の部分が2次元目のサイズとなっていましたが、「?」は本当に何を意味しているのか不明、「10」はその1次元目のサイズです。
総合して入力形状は float(または0vectorf)型のサイズ10を受け取ることがわかります。
//doubleの宣言方法
double inputName[10];
//vectorfの宣言方法
vectorf inputName(10);//[]ではなく()がポイント。「?」になる個人的な考えは、OnnxファイルをPythonで作成するときの使用するモジュールによるかなと考えてます。Noneを指定したときに、サイキットラーンでは「?」テンソーフローでは「-1」になっていました。追加情報あれば更新しやす
出力
名前:output_labelと、putput_probabilityの二つの出力値があります。
データ形状:output_labelはテンソル(配列)、putput_probabilityはsequence(シーケンス)であることがわかります。シーケンスは構造体です。この構造体の中身はラベルとその推論結果になります(あまり難しいこと言うとわけわからなくなりますので割愛します)。
データの型:output_labelはint配列(またはvector、vectorf配列でも可能)、putput_probabilityはint配列とfloat配列の構造体配列です。
データのサイズ:output_labelは一つ目は「?」。1次元目のサイズが指定されていませんので1です。putput_probabilityは指定がありませんので1ですが、動的配列でも可能でした。
総合して出力形状は2つint型のサイズ1の配列と、構造体(int , float)のサイズ1の配列を出力します。
//intの宣言方法
int out_1[1];
//構造体の宣言方法
struct output
{
long label[]; // ラベル用配列
float tensor[]; // 推論結果を格納するテンソル
};
output out_2[1];まとめ
オニックスファイルを実行するときに一番重要な関数について解説しましたが、まだまだ分からないことが多くフォーラムや情報量が少ない状態で手探りで調べています。間違っているところがあればこっそり教えてください(‘ω’)