
機械学習の世界で注目を集めているLightGBMとXGBoostは、多くのデータサイエンティストや機械学習エンジニアに愛用されている高性能な勾配ブースティング決定木(GBDT)モデルです。本記事では、これらのモデルについて以下の点を解説します:
- LightGBMとXGBoostの仕組みと特徴
- 両モデルの違いと性能比較
- Pythonでの実装方法
- 金融市場予測への応用例
- MQL5での活用方法
初心者から上級者まで、GBDTモデルの理解を深め、実践的なスキルを身につけたい方におすすめの内容です。
勾配ブースティングを理解するには線形モデルと非線形モデルを理解する必要があるよ。
線形モデルっていうのは身長と体重のように直線的な関係がある場合に使用、
非線形モデルは年齢と年収のように直線では表せないパターンを学習するときに使用するよ!
勾配ブースティング決定木とは?
勾配ブースティング決定木(GBDT)は、機械学習の世界で注目を集めている強力な手法です。主に予測(回帰)や分類のタスクに使用されます。
GBDTの基本的な考え方は、「三人寄れば文殊の知恵」ということわざに似ています。一人一人は完璧ではなくても、みんなで力を合わせれば素晴らしい結果が得られるという考え方です。GBDTでは、この「一人一人」を「弱い学習機」と呼びます。通常、これらは決定木(データの特徴に基づいて予測を行う単純なモデル)です。
GBDTの魅力は、これらの弱い学習機を順番に組み合わせて、徐々に予測の精度を上げていくところにあります。各ステップで新しいモデルが追加されるたびに、前のモデルの間違いを修正しようとします。これにより、最終的に非常に強力で精度の高い予測モデルが作られるのです。
主な概念
ブースティング
ブースティングは、GBDTの中核となる考え方です。簡単に言えば、「弱い力を集めて強い力にする」ということです。
例えば、あなたが新しい言語を学ぼうとしているとします。最初は単語をいくつか覚えるだけかもしれません。それだけでは会話はできませんが、少しずつ文法を学び、新しい単語を覚えていくことで、最終的には流暢に話せるようになります。
ブースティングも同じように、小さな改善を積み重ねて、最終的に強力なモデルを作り上げるのです。
複数のトレーダーが協力して出した最終判断ってとこかな
勾配降下法
勾配降下法は、モデルの予測と実際の値の差(これを「損失」と呼びます)を最小限に抑えるための方法です。
山登りの例で考えてみましょう。あなたが山の頂上(最適な予測)を目指しているとします。しかし、霧で周りが見えません。そんな時、最も急な斜面を探して、その方向に少しずつ進んでいけば、最終的に頂上にたどり着くことができるでしょう。これが勾配降下法の基本的な考え方です。
モデルは予測を少しずつ調整し、その都度「より良い」方向に進んでいきます。
Extreme Gradient Boosting (XGBoost)とは?
XGBoostは、GBDTの考え方を更に発展させた、高性能な機械学習ライブラリです。「Extreme」という名前が示すように、通常のGBDTよりも極端に効率的で、スケーラブル(大規模なデータにも対応できる)になるように設計されています。
XGBoostはどのように機能するのか?
XGBoostの動作は、次のような流れで進みます:
- 初期予測:まず、データの平均値などの簡単な予測から始めます。
- 反復的なブースティング:
a. 残差(誤差)の計算:現在のモデルの予測と実際の値の差を計算します。
b. 新しい決定木の作成:この残差を予測するための新しい決定木を作ります。
c. モデルの更新:新しい決定木の予測を現在のモデルに追加します。 - 目的関数の最小化:XGBoostは、予測の正確さと同時にモデルの複雑さも考慮します。これにより、過剰適合(訓練データに対しては非常に正確だが、新しいデータに対しては精度が落ちる状態)を防ぎます。
XGBoostの特徴は、これらのステップを非常に効率的に実行できるところにあります。また、並列処理や分散コンピューティングにも対応しているため、大規模なデータセットでも高速に動作します。
Light Gradient Boosting Machine (LightGBM)とは?
LightGBMは、MicrosoftによってXGBoostの競合として開発された、もう一つの高性能なGBDTライブラリです。その名前が示すように、「軽量」で高速な処理を特徴としています。
LightGBMの改善
LightGBMは、XGBoostと比較して以下のような改善を行っています:
- 高速な学習:LightGBMは、特殊なアルゴリズムを使用して学習速度を大幅に向上させています。
- メモリ効率:データの扱い方を工夫することで、必要なメモリ量を削減しています。
- 優れたスケーラビリティ:大規模なデータセットや分散学習に特に適しています。
- カテゴリ変数の直接サポート:カテゴリデータ(例:「赤」「青」「緑」など)を事前に数値に変換する必要がありません。
LightGBMの仕組み
LightGBMの主な特徴は以下の通りです:
- 葉優先成長:決定木を作る際、最も有望な葉(決定木の末端ノード)から優先的に成長させます。これにより、より深く複雑な木を効率的に作ることができます。
- Gradient-based One-Side Sampling (GOSS):全てのデータポイントを同等に扱うのではなく、重要なデータポイント(勾配が大きいもの)に焦点を当てます。これにより、計算量を減らしながら精度を維持します。
- Exclusive Feature Bundling (EFB):似たような特徴をグループ化することで、特徴の数を減らし、メモリ使用量と計算量を削減します。
これらの工夫により、LightGBMは特に大規模なデータセットで高速かつ効率的に動作します。
XGBoostとLightGBMの違い
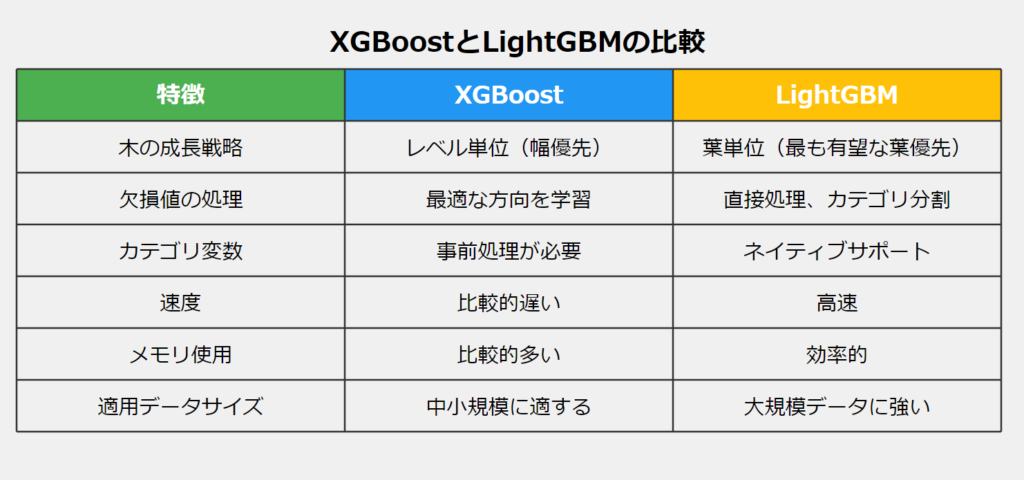
XGBoostとLightGBMは、どちらもGBDTの実装ですが、いくつかの重要な違いがあります:
木の成長戦略
- XGBoost:レベルごとに木を成長させます(幅優先)。
- LightGBM:葉ごとに木を成長させます(最も有望な葉を優先)。
欠損値の処理
- XGBoost:訓練中に欠損値を処理する最適な方向を学習します。
- LightGBM:欠損値を直接扱い、データを欠損のないカテゴリと欠損のカテゴリに分割します。
特徴の処理
- XGBoost:カテゴリ変数に対して事前処理(例:one-hotエンコーディング)が必要です。
- LightGBM:カテゴリ特徴量を直接サポートしています。
速度とメモリ使用
- XGBoost:一般的にLightGBMより遅く、メモリを多く使用します。
- LightGBM:高速で、メモリ効率が良いです。
適用範囲
- XGBoost:中小規模のデータセットに適しています。
- LightGBM:大規模データセットに特に適しています。
どちらを選ぶかは、データの性質や規模、計算リソースなどによって変わってきます。
PythonでXGBoostを実装する
XGBoostをPythonで実装する際は、主に以下のパラメータに注目します:
- objective:学習の目的(例:’binary:logistic’は2値分類)
- learning_rate:各ステップでの学習の大きさ
- max_depth:木の最大の深さ
- n_estimators:作成する木の数
- subsample:各木を作る際に使用するデータの割合
params = {
'objective': 'binary:logistic',
'learning_rate': 0.05,
'max_depth': 5,
'n_estimators': 100,
'colsample_bytree': 0.9,
'subsample': 0.9,
'eval_metric': ['auc', 'logloss']
}
pipe = Pipeline([
("scaler", StandardScaler()),
("xgb", xgb.XGBClassifier(**params))
])
# Fit the pipeline to the training data
pipe.fit(X_train, y_train)これらのパラメータを適切に調整することで、モデルの性能を向上させることができます。
PythonでLightGBMを実装する
LightGBMの実装では、以下のようなパラメータが重要です:
- boosting_type:ブースティングのタイプ(通常は’gbdt’)
- objective:学習の目的(例:’binary’は2値分類)
- num_leaves:1本の木の最大葉の数
- learning_rate:各ステップでの学習の大きさ
- feature_fraction:各ブースティングラウンドで使用する特徴量の割合
LightGBMは特にハイパーパラメータの調整に敏感なので、これらのパラメータを慎重に選ぶ必要があります。
params = {
'boosting_type': 'gbdt', # Gradient Boosting Decision Tree
'objective': 'binary', # For binary classification (use 'regression' for regression tasks)
'metric': ['auc','binary_logloss'], # Evaluation metric
'num_leaves': 25, # Number of leaves in one tree
'n_estimators' : 100, # number of trees
'max_depth': 5,
'learning_rate': 0.05, # Learning rate
'feature_fraction': 0.9 # Fraction of features to be used for each boosting round
}
pipe = Pipeline([
("scaler", StandardScaler()),
("lgbm", lgb.LGBMClassifier(**params))
])
# Fit the pipeline to the training data
pipe.fit(X_train, y_train)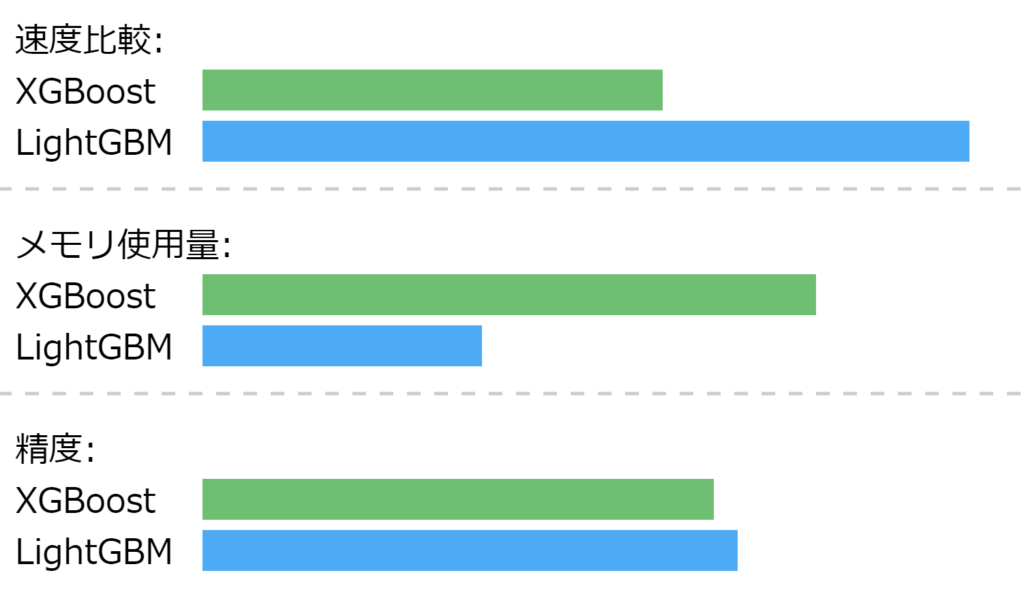
XGBoostとLightGBMをONNXに保存する
ONNX(Open Neural Network Exchange)は、機械学習モデルを異なるフレームワーク間で共有するための標準形式です。XGBoostとLightGBMのモデルをONNX形式で保存することで、異なる環境(例:Python環境からMQL5環境)でも同じモデルを使用することができます。
from skl2onnx.common.data_types import FloatTensorType
from skl2onnx import convert_sklearn, to_onnx, update_registered_converter
from skl2onnx.common.shape_calculator import calculate_linear_classifier_output_shapes
from onnxmltools.convert.xgboost.operator_converters.XGBoost import convert_xgboost
from onnxmltools.convert import convert_xgboost as convert_xgboost_booster
update_registered_converter(
lgb.LGBMClassifier,
"GBMClassifier",
calculate_linear_classifier_output_shapes,
convert_lightgbm,
options={"nocl": [False], "zipmap": [True, False, "columns"]},
)
model_onnx = convert_sklearn(
pipe,
"pipeline_lightgbm",
[("input", FloatTensorType([None, X_train.shape[1]]))],
target_opset={"": 12, "ai.onnx.ml": 2},
)
# And save.
with open("lightgbm.eurusd.h1.onnx", "wb") as f:
f.write(model_onnx.SerializeToString())
# XGBoostモデルの保存
update_registered_converter(
xgb.XGBClassifier,
"XGBClassifier",
calculate_linear_classifier_output_shapes,
convert_xgboost,
options={"nocl": [False], "zipmap": [True, False, "columns"]},
)
model_onnx = convert_sklearn(
pipe,
"pipeline_xgboost",
[("input", FloatTensorType([None, X_train.shape[1]]))],
target_opset={"": 12, "ai.onnx.ml": 2},
)
# And save.
with open("xgboost.eurusd.h1.onnx", "wb") as f:
f.write(model_onnx.SerializeToString())保存の際は、モデルの入力と出力の形状を正確に定義し、適切な変換関数を使用する必要があります。また、ONNXのバージョンにも注意が必要です。
このコードは非常に重要なコード、本家の記事も併せてブックマーク推奨
なぜかというと、ChatGPTが苦手としているから(‘Д’)
MQL5でONNXモデルを読み込む
MQL5でONNXモデルを読み込む際は、以下の手順を踏みます:
- ONNXライブラリをインポートする
- モデルのハンドルを取得する
- 入力と出力の形状を設定する
- モデルを初期化する
bool CLightGBM::OnnxLoad(long &handle)
{
//--- since not all sizes defined in the input tensor we must set them explicitly
//--- first index - batch size, second index - series size, third index - number of series (only Close)
OnnxTypeInfo type_info; //Getting onnx information for Reference In case you forgot what the loaded ONNX is all about
long input_count=OnnxGetInputCount(handle);
if (MQLInfoInteger(MQL_DEBUG))
Print("model has ",input_count," input(s)");
for(long i=0; i<input_count; i++)
{
string input_name=OnnxGetInputName(handle,i);
if (MQLInfoInteger(MQL_DEBUG))
Print(i," input name is ",input_name);
if(OnnxGetInputTypeInfo(handle,i,type_info))
{
if (MQLInfoInteger(MQL_DEBUG))
PrintTypeInfo(i,"input",type_info);
ArrayCopy(inputs, type_info.tensor.dimensions);
}
}
long output_count=OnnxGetOutputCount(handle);
if (MQLInfoInteger(MQL_DEBUG))
Print("model has ",output_count," output(s)");
for(long i=0; i<output_count; i++)
{
string output_name=OnnxGetOutputName(handle,i);
if (MQLInfoInteger(MQL_DEBUG))
Print(i," output name is ",output_name);
if(OnnxGetOutputTypeInfo(handle,i,type_info))
{
if (MQLInfoInteger(MQL_DEBUG))
PrintTypeInfo(i,"output",type_info);
ArrayCopy(outputs, type_info.tensor.dimensions);
}
}
//---
replace(inputs);
replace(outputs);
//--- Setting the input size
for (long i=0; i<input_count; i++)
if (!OnnxSetInputShape(handle, i, inputs)) //Giving the Onnx handle the input shape
{
printf("Failed to set the input shape Err=%d",GetLastError());
DebugBreak();
return false;
}
//--- Setting the output size
for(long i=0; i<output_count; i++)
{
if(!OnnxSetOutputShape(handle,i,outputs))
{
printf("Failed to set the Output[%d] shape Err=%d",i,GetLastError());
//DebugBreak();
//return false;
}
}
initialized = true;
Print("ONNX model Initialized");
return true;
}MQL5では、ONNXモデルの読み込みと使用に関する特有の制約や注意点があるため、それらに留意しながら実装を進める必要があります。
ONNXの形状を理解するために、こういうサンプル記事は助かるね
取引におけるLightGBMとXGBoostの使用
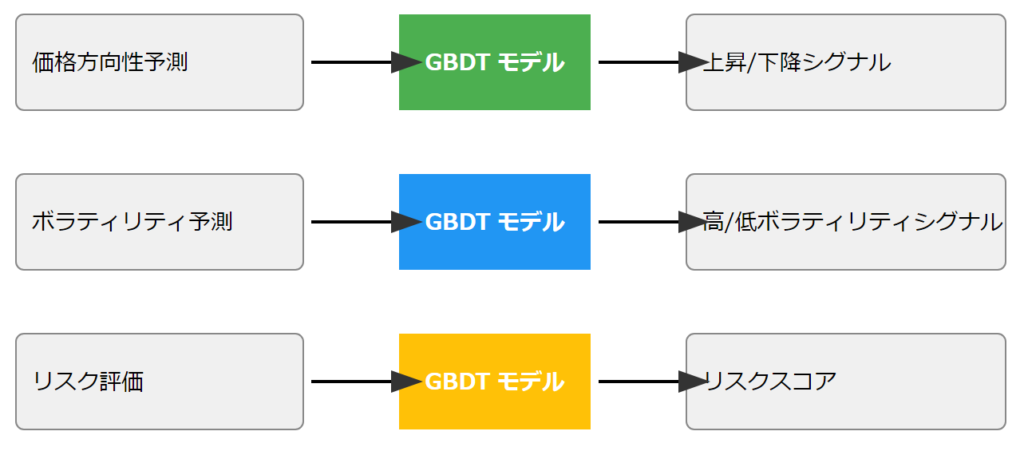
LightGBMとXGBoostは、金融市場の予測タスクに非常に適しています。例えば、次のような使い方が考えられます:
- 価格の方向性予測:次の期間(例:1時間後)の価格が上がるか下がるかを予測
- ボラティリティ予測:市場の変動の大きさを予測
- リスク評価:取引のリスクレベルを評価
void OnTick()
{
int size = CopyRates(Symbol(), PERIOD_CURRENT, 1, 1, rates_x); //We copy only one recent-closed bar
//---
if (NewBar())
{
vector x = {
rates_x[0].open,
rates_x[0].high,
rates_x[0].low,
rates_x[0].close,
rates_x[0].close-rates_x[0].open,
rates_x[0].high-rates_x[0].low,
rates_x[0].close-rates_x[0].low,
rates_x[0].close-rates_x[0].high
};
long signal = lgbm.predict_bin(x);
Comment("Signal: ",signal);
}これらのモデルを使用する際は、以下の点に注意が必要です:
- 適切な特徴量の選択:価格データだけでなく、テクニカル指標やファンダメンタル指標なども考慮
- 過去のデータで十分にテスト:バックテストを行い、モデルの性能を評価
- 定期的な再訓練:市場の状況は常に変化するため、定期的にモデルを更新する
また、これらのモデルは予測ツールであり、完璧ではないことを理解し、リスク管理と組み合わせて使用することが重要です。
勾配ブースティング決定木のメリット・デメリット
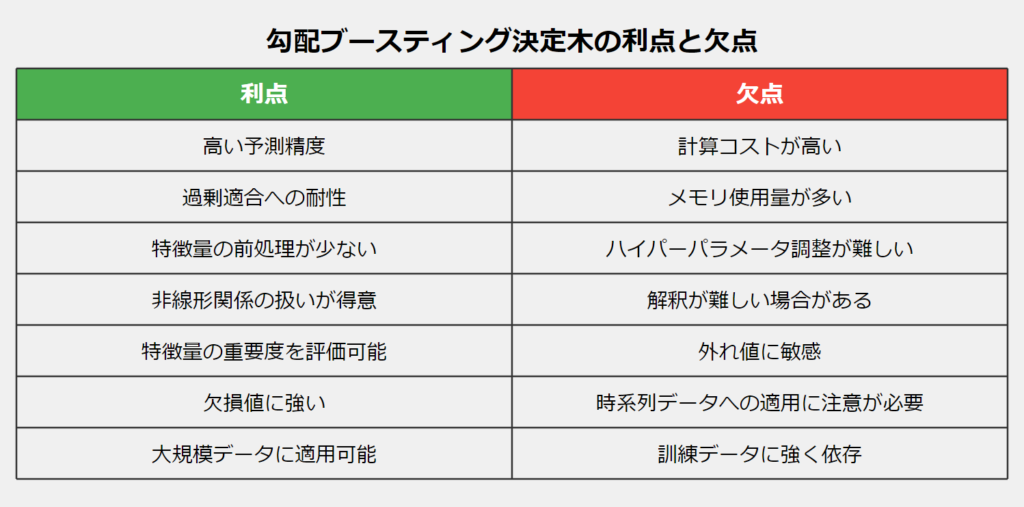
メリット
GBDTには多くの利点があります:
- 高い予測精度:多くの場合、他の機械学習アルゴリズムよりも高い精度を達成します。
- 過剰適合への耐性:ブースティングのプロセスにより、過剰適合を抑制する傾向があります。
- 特徴量の前処理が少なくて済む:特徴量のスケーリングや正規化があまり必要ありません。
- 非線形関係の扱いが得意:複雑な特徴間の関係を自動的に学習できます。
- 特徴量の重要度を評価可能:どの特徴がモデルの予測に重要かを理解しやすいです。
- 欠損値に強い:多くの実装で欠損値を自然に扱えます。
- 大規模データに適用可能:特にLightGBMは大規模データセットで効率的に動作します。
これらの利点により、GBDTは多くのデータサイエンスコンペティションで優勝モデルとして選ばれています。
デメリット
一方で、GBDTにはいくつかの欠点もあります:
- 計算コストが高い:特に深い木や多数の木を使用する場合、訓練に時間がかかることがあります。
- メモリ使用量が多い:大規模なデータセットでは、メモリ不足になる可能性があります。
- ハイパーパラメータの調整が難しい:最適なパフォーマンスを得るには、多くのパラメータを適切に設定する必要があります。
- 解釈が難しい場合がある:単一の決定木に比べると、モデル全体の動作を理解するのが難しい場合があります。
- 外れ値に敏感:外れ値がモデルの性能に大きな影響を与える可能性があります。
- 時系列データへの適用に注意が必要:時系列の依存関係を自動的に学習することはできないため、適切な特徴エンジニアリングが必要です。
- 訓練データに強く依存:訓練データの品質と代表性が結果に大きく影響します。
- これらの欠点を理解し、適切に対処することで、GBDTの強力な予測能力を最大限に活用することができます。
決定木は基本的にはCPUで学習させるから計算コストが高くなっちゃうんだよね
時系列データへの適用にはAI搭載EA研究所で研究中!
まとめ
勾配ブースティング決定木(GBDT)、特にXGBoostとLightGBMは、多くの機械学習タスク、とりわけ金融市場の予測において非常に強力なツールとなっています。これらのモデルが多くのAIモデルを凌駕する理由は以下のとおりです:
- 高い予測精度:複雑な非線形関係を効果的に学習し、高い予測精度を実現します。
- 効率性:特にLightGBMは、大規模なデータセットでも高速に動作し、メモリ効率も優れています。
- 柔軟性:様々な種類のデータや問題に適用可能で、カテゴリ変数や欠損値も効果的に扱えます。
- 解釈可能性:特徴量の重要度を評価できるため、モデルの判断根拠を理解しやすいです。
- 過剰適合への耐性:ブースティングのプロセスと正則化技術により、過剰適合を抑制しやすいです。
- 少ない前処理:特徴量のスケーリングや正規化があまり必要ないため、データ準備の手間が省けます。
ただし、これらのモデルにも欠点があることを忘れてはいけません。計算コストが高い、ハイパーパラメータの調整が難しい、時系列データへの適用に注意が必要、などの点に留意する必要があります。
XGBoostとLightGBMは、その高い性能と使いやすさから、データサイエンティストや機械学習エンジニアの間で非常に人気が高くなっています。しかし、これらのツールを効果的に使用するためには、その仕組みと特性を十分に理解することが必要です。
大事なのは、どんなデータをどういう形で学習させるか
扱いやすい決定木でもポイントがあるのだ(‘ω’)
オンラインコミュニティ
こちらのコミュニティで、AIや機械学習をトレードに活かすために日々探求しています。
興味のある方は覗いてみてください。
参考記事
