
AIを活用したトレードは、金融市場に革新をもたらしています。本記事では、初心者でも扱いやすいCatBoostを使って、AIシステムを構築する方法を解説します。主な内容は以下の通りです:
- AIトレードの基礎と利点
- CatBoostの特徴と使い方
- 市場データの収集と前処理
- 効果的な特徴量の作成
- CatBoostでのモデル構築と過学習の防止
- MT5での実装方法
- バックテストと実運用のポイント
プログラミング初心者の方でも理解しやすいよう、段階的に説明していきます。この記事を通じて、AIを活用した効率的な投資の第一歩を踏み出しましょう。
本モデルはXGBoost、LightGBMの兄弟みたいな機械学習モデルだよ(‘ω’)
1. AIトレーディングの基礎
1.1 AIが金融市場にもたらす変革
AIトレーディングは、コンピューターが自動的に株や為替を取引する方法です。人間の代わりにAIが市場を分析し、売買の判断を行います。
AIトレーディングの主なメリット:
- 膨大なデータを素早く分析できる
- 感情に左右されず冷静な判断ができる
- 24時間休まずに市場を監視できる
- 複雑なパターンを見つけ出せる
ただし、AIにも課題があります。例えば、予想外の出来事への対応が苦手だったり、システムの判断根拠が不明確になりがちです。
1.2 CatBoost入門:初心者でも使える強力なツール

CatBoostは、AIトレーディングに使える便利なツールです。主な特徴は以下の通りです:
- 高い予測精度:他の似たようなツールより正確な予測ができます
- 使いやすさ:プログラミング初心者でも扱いやすい設計になっています
- 自動的なデータ処理:データの前処理を自動で行ってくれます
- 過学習への強さ:データに過剰に適合してしまう問題を防ぎます
from catboost import CatBoostClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# データ準備
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデル初期化と学習
model = CatBoostClassifier(iterations=1000, learning_rate=0.1, depth=6)
model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=50, verbose=100)
# 予測と評価
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print(f"Model accuracy: {accuracy:.4f}")
# 特徴量の重要度表示
feature_importance = model.get_feature_importance()
for i, importance in enumerate(feature_importance):
print(f"Feature {i}: {importance}")CatBoostは特に、カテゴリーデータ(例:曜日や株式の業種など)の処理が得意です。これは金融データを扱う上で大きな利点となります。
金融市場の必要としてるカテゴリーは買うか売るかの二択だからね
それでもって過学習に強いのは金融市場向けに作られたといっても過言ではない(‘Д’)
2. 市場データの活用法
2.1 取引データの収集と前処理
AIトレーディングには、質の良いデータが欠かせません。以下の手順でデータを準備します:
- データの収集:取引所やデータ提供会社から株価や為替レートなどのデータを入手します
- データのクリーニング:誤ったデータや欠損値を修正・除去します
- データの整形:AIが理解しやすい形式にデータを変換します
import pandas as pd
def get_prices() -> pd.DataFrame:
p = pd.read_csv('EURUSD_H1.csv', delim_whitespace=True)
pFixed = pd.DataFrame(columns=['time', 'close'])
pFixed['time'] = p['<DATE>'] + ' ' + p['<TIME>']
pFixed['time'] = pd.to_datetime(pFixed['time'], format='mixed')
pFixed['close'] = p['<CLOSE>']
pFixed.set_index('time', inplace=True)
pFixed.index = pd.to_datetime(pFixed.index, unit='s')
return pFixed.dropna()注意点として、将来のデータを誤って使用しないよう気をつける必要があります。これを「先読みバイアス」と呼びます。
2.2 特徴量の作成:AIの判断材料を設計する
特徴量とは、AIが判断を下すために使う情報のことです。例えば:
- 価格の動き:株価の上昇・下降傾向
- テクニカル指標:移動平均線やRSIなど
- 市場の雰囲気:ニュースの sentiment(感情)分析
- 経済指標:GDP、インフレ率など
def calculate_ma(data, window):
return data['close'].rolling(window=window).mean()
data['MA_10'] = calculate_ma(data, 10)
data['MA_50'] = calculate_ma(data, 50)
data['MA_diff'] = data['MA_10'] - data['MA_50']
data['daily_return'] = data['close'].pct_change()
data['volatility'] = data['daily_return'].rolling(window=20).std()
data['day_of_week'] = data.index.dayofweek
data['month'] = data.index.monthCatBoostの良いところは、日付や曜日などのカテゴリーデータをそのまま使えることです。これにより、データ準備の手間が大幅に減ります。
深層学習で時間を扱う場合はサイクリックエンコーディングなどの正規化が必要
3. CatBoostで学習モデルを構築
3.1 モデル作成の手順:基本から応用まで
CatBoostでモデルを作る基本的な手順は以下の通りです:
- データの準備:特徴量とターゲット(予測したい値)を用意
- データの分割:訓練用と検証用にデータを分ける
- モデルの初期化:CatBoostClassifierやCatBoostRegressorを設定
- モデルの学習:fit()メソッドを使ってデータを学習させる
- 予測と評価:学習したモデルで予測を行い、精度を確認する
from catboost import CatBoostClassifier
from sklearn.model_selection import TimeSeriesSplit
# 時系列交差検証
tscv = TimeSeriesSplit(n_splits=5)
for train_index, test_index in tscv.split(X):
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
model = CatBoostClassifier(iterations=1000)
model.fit(X_train, y_train, eval_set=(X_test, y_test))
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print(f"Fold accuracy: {accuracy:.4f}")応用テクニックとしては、複数のモデルを組み合わせたり、時系列データ特有の検証方法を使ったりします。
3.2 過学習の防止:信頼性の高いモデルの作り方
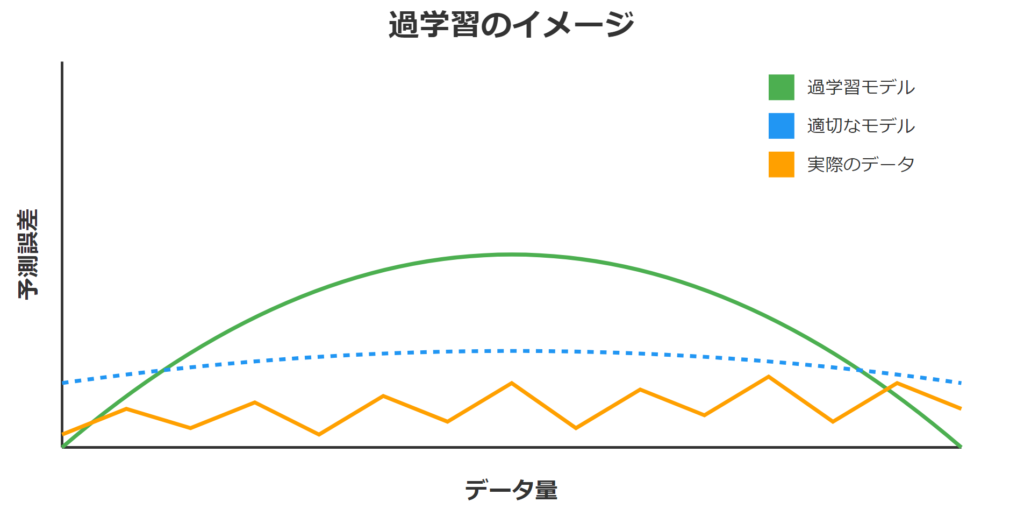
過学習とは、モデルが訓練データに過度に適合してしまい、新しいデータで正確な予測ができなくなる問題です。防止策として:
- 適切なデータ分割:訓練データと検証データを適切に分ける
- 正則化:モデルが複雑になりすぎないようにする
- 早期停止:学習の途中で適切なタイミングで止める
- クロスバリデーション:複数の検証パターンで性能を確認する
model = CatBoostClassifier(
iterations=5000,
learning_rate=0.01,
depth=6,
l2_leaf_reg=3,
bootstrap_type='Bayesian',
bagging_temperature=1
)
model.fit(X_train, y_train, eval_set=(X_val, y_val), early_stopping_rounds=100, verbose=100)CatBoostには過学習を防ぐ機能が備わっていますが、これらの方法を組み合わせるとより信頼性の高いモデルが作れます。
4. MT5での実装
4.1 ONNXの活用:学習モデルを取引システムに組み込む
ONNXは、異なるAIツール間でモデルを共有するための形式です。CatBoostで作ったモデルをONNX形式に変換し、MT5で使うことができます。
手順:
- CatBoostモデルをONNX形式に変換
- MetaTrader 5用のコードを生成
- MetaTrader 5でONNXモデルを使用
def export_model_to_ONNX(model, model_number):
model.save_model(
f'catmodel{model_number}.onnx',
format="onnx",
export_parameters={
'onnx_domain': 'ai.catboost',
'onnx_model_version': 1,
'onnx_doc_string': 'CatBoost model for trading',
'onnx_graph_name': 'CatBoostModel_for_trading'
})
print(f'Model exported as catmodel{model_number}.onnx')
# モデルをエクスポート
export_model_to_ONNX(trained_model, 1)この方法を使えば、Pythonで作った高度なモデルをMetaTrader 5の取引システムに簡単に組み込めます。
4.2 自動売買システムの開発と調整
自動売買システムを作る際の重要なポイント:
- リスク管理:損失を抑えるための仕組みを作る
- シグナルフィルター:誤った売買シグナルを減らす
- パフォーマンス監視:システムの性能を常にチェックする
- 複数の時間枠:短期と長期の分析を組み合わせる
void OnTick() {
if(!isNewBar())
return;
double features[];
fill_arays(features);
double f[ArraySize(Periods)];
int k = ArraySize(Periods) - 1;
for(int i = 0; i < ArraySize(Periods); i++) {
f[i] = features[i];
k--;
}
static vector out(1), out_meta(1);
struct output {
long label[];
float tensor[];
};
output out2[], out2_meta[];
OnnxRun(ExtHandle, ONNX_DEBUG_LOGS, f, out, out2);
OnnxRun(ExtHandle2, ONNX_DEBUG_LOGS, f, out_meta, out2_meta);
double sig = out2[0].tensor[1];
double meta_sig = out2_meta[0].tensor[1];
if(meta_sig > 0.5)
if(count_market_orders(0) || count_market_orders(1))
for(int b = OrdersTotal() - 1; b >= 0; b--)
if(OrderSelect(b, SELECT_BY_POS) == true) {
if(OrderType() == 0 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig > 0.5)
if(SymbolInfoInteger(_Symbol, SYMBOL_TRADE_FREEZE_LEVEL) < MathAbs(Bid - OrderOpenPrice())) {
int res = -1;
do {
res = OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red);
Sleep(50);
} while (res == -1);
}
if(OrderType() == 1 && OrderSymbol() == _Symbol && OrderMagicNumber() == OrderMagic && sig < 0.5)
if(SymbolInfoInteger(_Symbol, SYMBOL_TRADE_FREEZE_LEVEL) < MathAbs(Bid - OrderOpenPrice())) {
int res = -1;
do {
res = OrderClose(OrderTicket(), OrderLots(), OrderClosePrice(), 0, Red);
Sleep(50);
} while (res == -1);
}
}
if(meta_sig > 0.5)
if(countOrders() < max_orders && CheckMoneyForTrade(_Symbol, LotsOptimized(meta_sig), ORDER_TYPE_BUY)) {
double l = LotsOptimized(meta_sig);
if(sig < 0.5) {
int res = -1;
do {
double stop = Bid - stoploss * _Point;
double take = Ask + takeprofit * _Point;
res = OrderSend(Symbol(), OP_BUY, l, Ask, 0, stop, take, comment, OrderMagic);
Sleep(50);
} while (res == -1);
} else {
if(sig > 0.5) {
int res = -1;
do {
double stop = Ask + stoploss * _Point;
double take = Bid - takeprofit * _Point;
res = OrderSend(Symbol(), OP_SELL, l, Bid, 0, stop, take, comment, OrderMagic);
Sleep(50);
} while (res == -1);
}
}
}これらを適切に設定することで、安定した自動売買システムを作ることができます。
5. 実践と検証
5.1 バックテストの正しい進め方
バックテストとは、過去のデータを使って取引戦略の性能を確認することです。正しく行うためのポイント:
- 十分な期間のデータを使う
- 取引コスト(手数料など)を考慮する
- 適切な評価指標を使う(単なる利益だけでなく、リスクも考慮)
- 過去のデータに過度に最適化しない
- 様々な市場環境でテストする
5.2 実口座での運用:リスク管理の重要性
実際にお金を使って取引を行う際は、以下の点に注意が必要です:
- 少額から始める:システムの性能を確認しながら徐々に資金を増やす
- 常に監視する:異常がないか定期的にチェックする
- リスク管理ルールを守る:事前に決めた損失限度を厳守する
- 市場の変化に適応する:必要に応じてモデルを再学習させる
- 緊急停止の準備:問題が発生した際にすぐシステムを止められるようにする
6. まとめ:AIトレーディングの未来と可能性
AIトレーディングは日々進化しており、個人投資家にも大きなチャンスをもたらしています。CatBoostのような使いやすいツールのおかげで、専門知識がなくてもAIを活用した取引が可能になってきました。
ただし、技術だけでなく、市場への理解や倫理的な配慮も重要です。AIの力を借りつつ、自分の頭で考え、責任ある取引を心がけることが大切です。
CatBoostはAIトレードの中でも実際に使われているモデルということを裏付ける結果が出てきています(‘Д’)
どんな結果がでてるかはオンラインコミュニティで公開してるよ
オンラインコミュニティ
こちらのコミュニティで、AIや機械学習をトレードに活かすために日々探求しています。
興味のある方は覗いてみてください。
参考記事
記事本文のコードは下記の記事の内容を引用しています。
