FX取引の世界で、人工知能が新たな地平を切り開いています。本記事では、最先端の深層学習モデルであるGRU(ゲート付き回帰型ユニット)とLSTM(長短期記憶)を徹底比較。
これらのモデルがどのようにFX市場の予測精度を向上させ、トレーダーに革命的な武器をもたらすのかを解説します。AI時代のFX取引戦略を身につけたい方必見の内容です。
- GRUとLSTMの基本構造と特徴
- FX取引における深層学習モデルの応用事例
- モデル選択のポイントと実装のヒント
- 将来の展望:AI driven tradingの可能性
GRUとLSTMの比較は非常に気になるよね(‘ω’)
機械学習モデルの基本
決定木
機械学習の基本的なモデルとして、決定木を例に挙げて説明します。決定木は、データを特定の基準に基づいて分割し、予測や分類を行うシンプルなモデルです。例えば、住宅価格の予測において、ベッドルーム数や敷地面積などの特徴を使用して、データを分割し予測を行います。
決定木の利点は解釈のしやすさですが、複雑なパターンを捉えるには限界があります。そのため、より高度なモデルが必要となります。
モデル容量
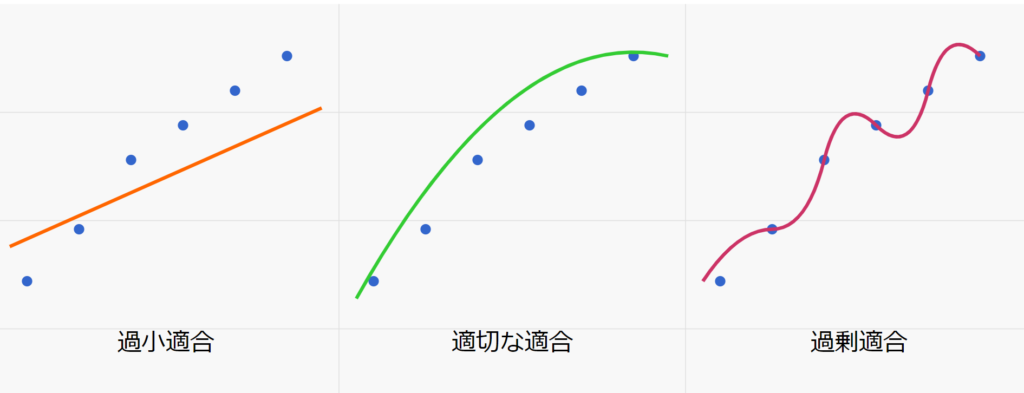
モデル容量とは、モデルが複雑なパターンを学習し表現する能力を指します。ニューラルネットワークの文脈では、これはニューロンの数と層の深さによって決定されます。モデル容量が低すぎると「過小適合」が、高すぎると「過剰適合」が起こる可能性があります。
適切なモデル容量を選択するには、データの複雑さとサイズ、問題の性質を考慮する必要があります。モデルの幅(各層のユニット数)を広げるか、深さ(層の数)を増やすことで、モデル容量を調整できます。
過剰適合はAIの分野でも永遠のテーマだね
ゲート付き回帰型ユニット(GRU)
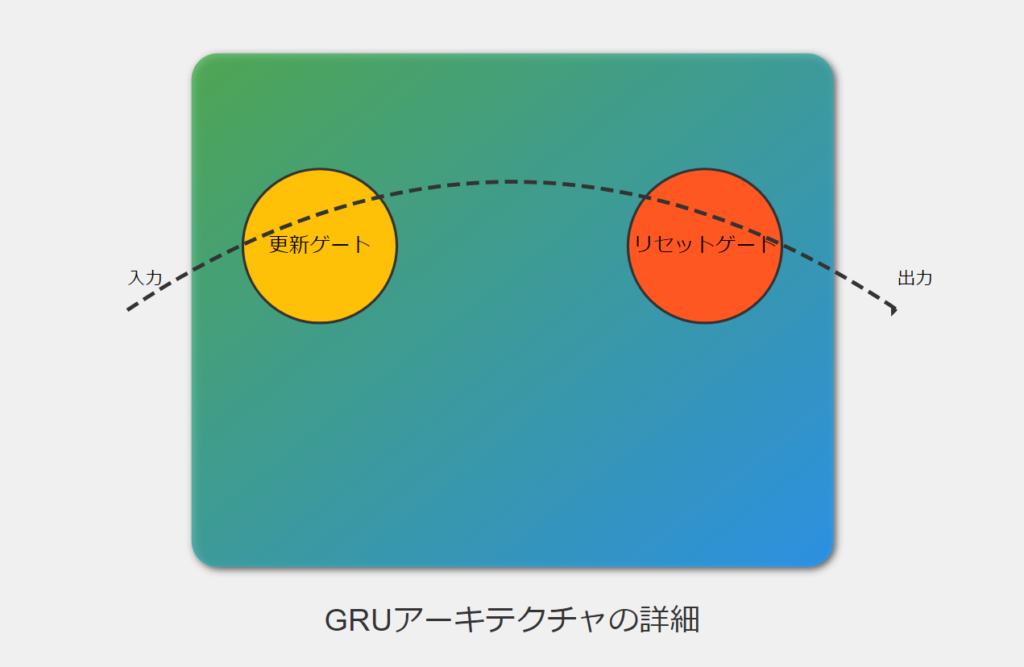
GRUの仕組み
GRUは、長期依存性を学習するために設計された回帰型ニューラルネットワーク(RNN)の一種です。LSTMの簡略化バージョンとも言えるGRUは、更新ゲートとリセットゲートの2つのゲートを使用して情報の流れを制御します。
- 更新ゲート:新しい情報をどの程度保持するかを決定します。
- リセットゲート:過去の情報をどの程度忘れるかを制御します。
これらのゲートにより、GRUは長期的な依存関係を効率的に学習し、勾配消失問題を軽減することができます。
GRUモデルの構築
Kerasを使用してGRUモデルを構築する例を以下に示します:
model = Sequential()
model.add(Dense(128, activation='relu', input_shape=(X_train.shape[1],), kernel_regularizer=l2(k_reg)))
model.add(Dense(256, activation='relu', kernel_regularizer=l2(k_reg)))
model.add(Dense(128, activation='relu', kernel_regularizer=l2(k_reg)))
model.add(Dense(64, activation='relu', kernel_regularizer=l2(k_reg)))
model.add(Dense(1, activation='linear'))このモデルは、複数の全結合層(Dense)を使用し、活性化関数としてReLU(Rectified Linear Unit)を採用しています。最後の層は線形活性化を使用し、回帰問題に適した出力を生成します。
GRUモデルを構築する例として取り上げられているコードのはずが
Denseモデルという誤記事の可能性があり!?
モデルのコンパイルと訓練
損失関数
損失関数は、モデルの予測と実際の値との差を測定します。回帰問題では、一般的に平均二乗誤差(MSE)や平均絶対誤差(MAE)が使用されます。
model.compile(optimizer='adam', loss='mean_squared_error')MSEは二乗するから小さい誤差の判定が難しくなるよ(‘Д’)
オプティマイザー
オプティマイザーは、損失関数を最小化するようにモデルのパラメータを更新します。Adam(Adaptive Moment Estimation)は、学習率を動的に調整する人気のオプティマイザーです。
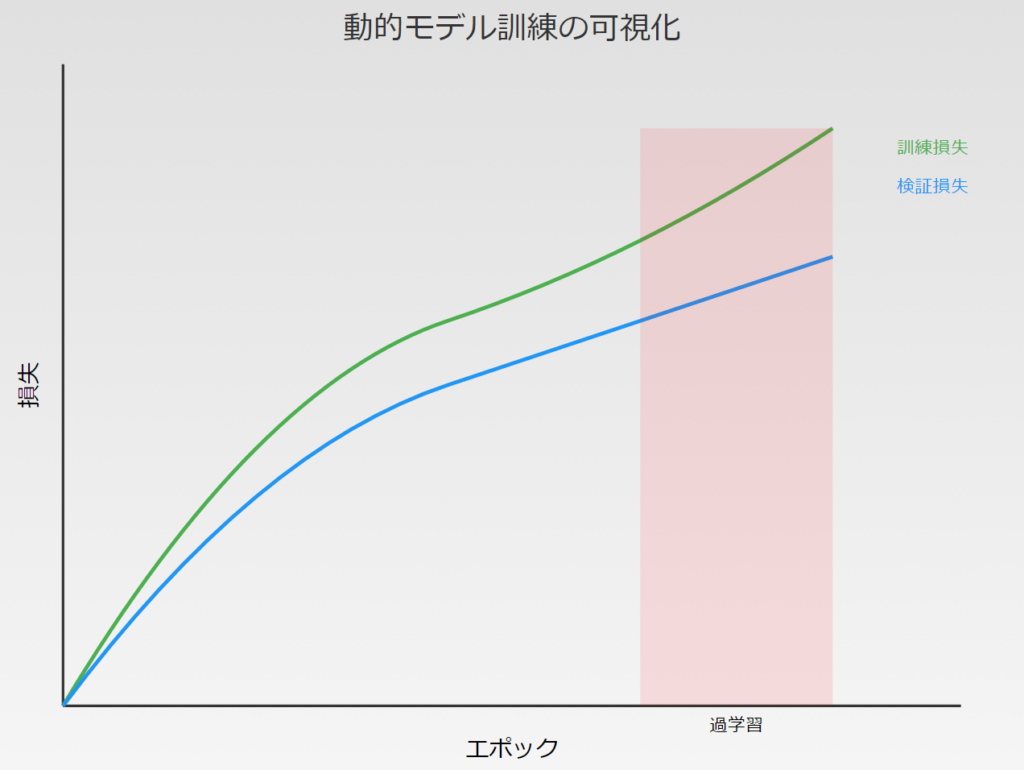
過剰適合と過小適合
過剰適合は、モデルが訓練データに対して過度に最適化され、新しいデータに対する一般化能力が低下する現象です。一方、過小適合は、モデルが訓練データのパターンを十分に学習できていない状態を指します。
これらの問題に対処するために、以下の手法が用いられます:
- クロスバリデーション
- 正則化(L1、L2正則化)
- ドロップアウト
- データ拡張
早期停止
早期停止は、過剰適合を防ぐための技術です。検証セットの性能が改善しなくなった時点で訓練を停止します。
early_stopping = callbacks.EarlyStopping(
min_delta=0.001, # minimium amount of change to count as an improvement
patience=20, # how many epochs to wait before stopping
restore_best_weights=True,
)この例では、20エポック連続で検証損失が0.001以上改善しない場合に訓練を停止し、最良の重みを復元します。
データの前処理
欠損値の処理
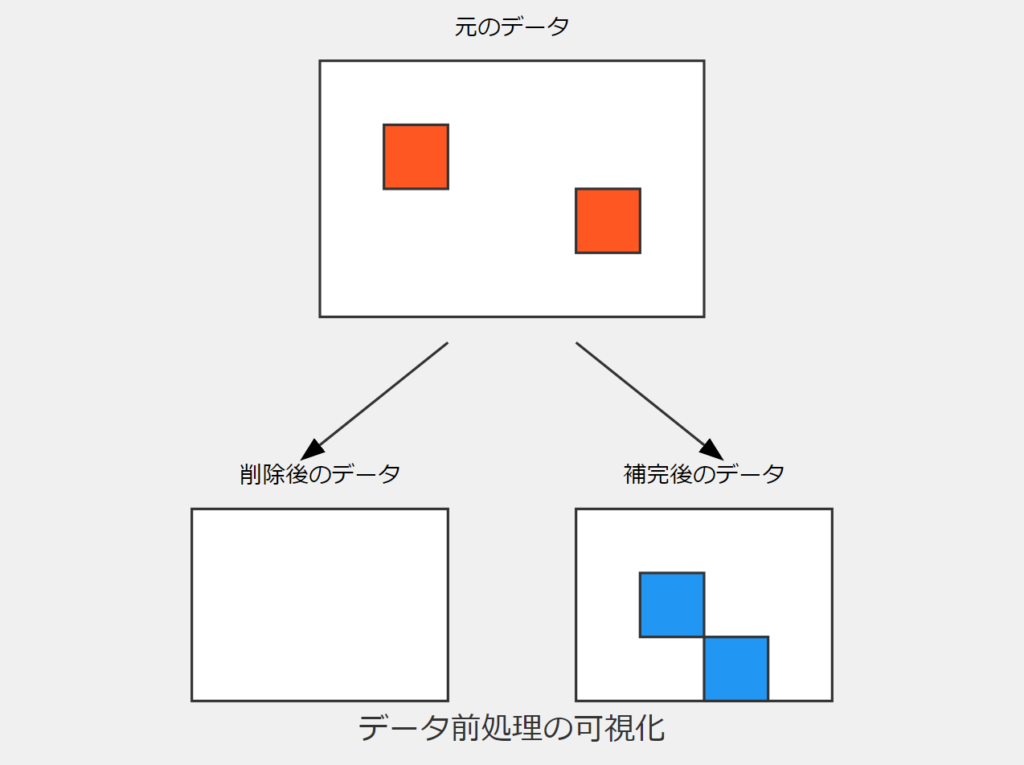
欠損値の処理は、機械学習モデルの性能に大きな影響を与える重要なステップです。主な方法として以下があります:
- 欠損値を含む行や列の削除
- 平均値、中央値、または他の統計量による代入
- 高度な代入技術(多重代入法など)
選択する方法は、欠損値の割合、欠損のメカニズム、およびデータの性質に依存します。
ONNXモデルの出力
データの読み込み
MetaTrader 5からデータを読み込む例:
eurusd_rates = mt5.copy_rates_range("EURUSD", mt5.TIMEFRAME_H1, start_date, end_date)
df = pd.DataFrame(eurusd_rates)このコードは、指定された期間のEUR/USDの1時間足データを取得し、Pandasデータフレームに変換します。
モデルの訓練結果
GRUモデルの訓練結果の例:
Mean Squared Error: 0.0031695919830203693
Mean Absolute Error: 0.05063149001883482
R2 Score: 0.9263800140852619
Baseline MSE: 0.0430534174061265
Baseline MAE: 0.18048216851868318
Baseline R2 Score: 0.0これらの結果は、モデルが単純なベースラインモデルと比較して大幅に優れていることを示しています。R2スコアが0.92であることは、モデルがデータの変動の92%を説明できていることを意味します。
LSTMとGRUの比較
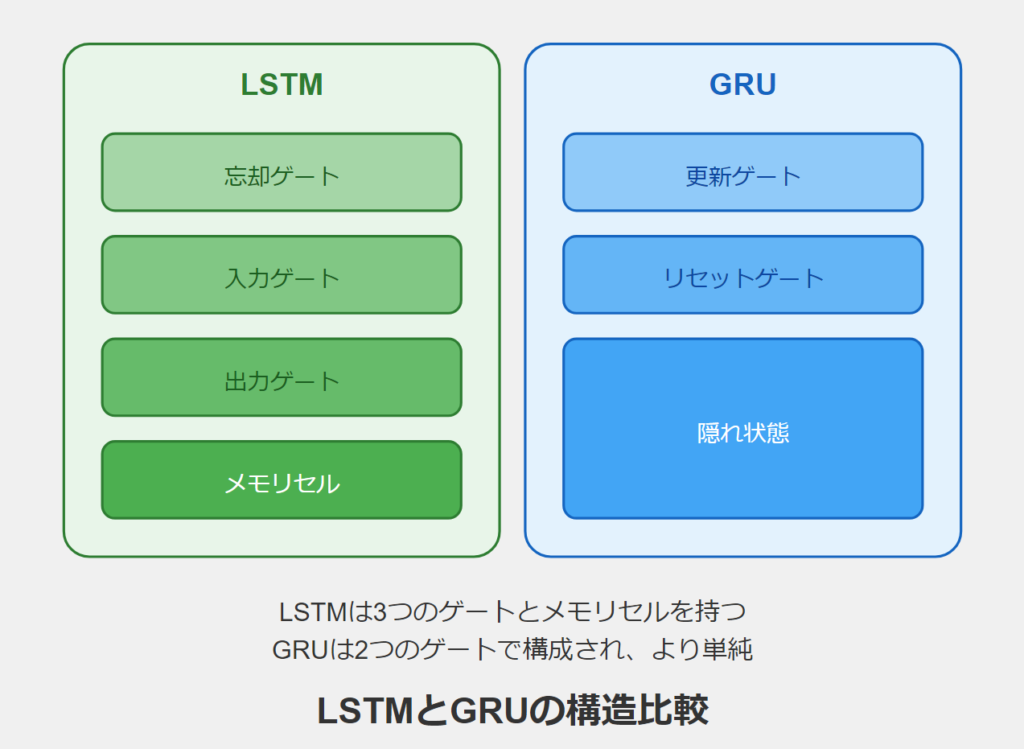
アーキテクチャの違い
LSTM(Long Short-Term Memory)とGRU(Gated Recurrent Unit)は、両方とも長期依存性を学習するために設計された回帰型ニューラルネットワークのアーキテクチャですが、いくつかの重要な違いがあります:
ゲートの数:
- LSTM:入力ゲート、忘却ゲート、出力ゲートの3つのゲートを持つ
- GRU:更新ゲートとリセットゲートの2つのゲートを持つ
メモリセル:
- LSTM:明示的なメモリセルを持つ
- GRU:明示的なメモリセルを持たず、隠れ状態が直接更新される
パラメータ数:
- LSTM:より多くのパラメータを持ち、より複雑
- GRU:より少ないパラメータを持ち、より単純
計算効率:
- GRUは一般的にLSTMよりも計算効率が高く、訓練が速い
パフォーマンス:
- タスクや数据セットによって異なるが、多くの場合で同等のパフォーマンスを示す
実験的比較
LSTMとGRUの実験的比較を行うために、同じデータセットに対して両方のモデルを訓練し、その性能を評価しました。以下は、それぞれのモデルアーキテクチャの例です:
model = Sequential()
model.add(Conv1D(filters=256, kernel_size=2, activation='relu',padding = 'same',input_shape=(inp_history_size,1)))
model.add(MaxPooling1D(pool_size=2))
model.add(LSTM(100, return_sequences = True))
model.add(Dropout(0.3))
model.add(LSTM(100, return_sequences = False))
model.add(Dropout(0.3))
model.add(Dense(units=1, activation = 'sigmoid'))
model.compile(optimizer='adam', loss= 'mse' , metrics = [rmse()])両モデルを同じデータセットで訓練し、MSE(平均二乗誤差)、MAE(平均絶対誤差)、R2スコアなどの指標を比較しました。
こちらはしっかりとLSTMが使われているモデルになります(‘Д’)
LSTMのところをGRUに書き換えれば概ねGRUのモデルになるかと思います
スライディングウィンドウ評価
時系列データの評価には、スライディングウィンドウ法を使用しました。この方法では、固定サイズのウィンドウをデータセット上で移動させながら、モデルの性能を評価します。これにより、モデルの時間的な一般化能力をより適切に評価できます。
def create_windows(data, window_size):
return [data[i:i + window_size] for i in range(len(data) - window_size + 1)]
x_train_windows = create_windows(x_train_fold_flat, window_size)
x_val_windows = create_windows(x_val_fold_flat, window_size)この評価方法により、モデルが異なる時間帯でどのように機能するかを理解し、過去のデータに過度に適合していないことを確認できます。
まとめ
この研究を通じて、GRUとLSTMの両モデルが金融時系列データの予測に有効であることが示されました。GRUモデルは、より少ないパラメータ数で同等の性能を示し、計算効率の面で優位性がありました。
今後の課題として以下が挙げられます:
- より長期の時系列データでのモデルの性能評価
- 異なる市場条件下でのモデルの堅牢性の検証
- モデルの解釈可能性の向上
- リアルタイムデータでのモデルの性能評価
- 他の機械学習モデル(例:変換器ベースのモデル)との比較
また、ONNXフォーマットを使用してモデルをMetaTrader 5のEAに統合する方法をさらに探求し、実際の取引環境での性能を評価することも重要です。
GRUとLSTMの精度はとても似ていてどちらも有効
甲乙つけ難しってところだね
オンラインコミュニティ
こちらのコミュニティで、AIや機械学習をトレードに活かすために日々探求しています。
興味のある方は覗いてみてください。
参考記事
記事本文のコードは下記の記事の内容を引用しています。
