
FXにAI(機械学習)を活用するとき、多くの人が悩むのが「分類」と「回帰」のどちらを使うべきかという問題です。
この記事では、それぞれの特徴・難易度・向いているケースを整理し、FXトレードにおける実用的な使い分けを解説します。
そもそも「分類」と「回帰」の違いは?
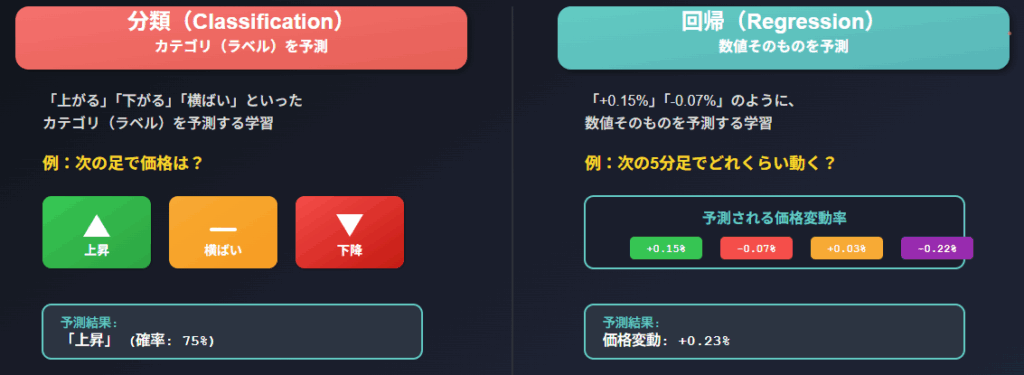
- 分類(Classification)
→ 「上がる」「下がる」「横ばい」といったカテゴリ(ラベル)を予測する学習。
(例)次の足で価格は上昇か、下降か、それとも変わらないか? - 回帰(Regression)
→ 「+0.15%」「−0.07%」のように、数値そのものを予測する学習。
(例)次の5分足で価格がどれくらい動くか?
分類学習が向いているケース
分類は「方向性」や「状態」をシンプルに当てたいときに強いです。
- 価格の方向予測
(次の足が「上がる/下がる/横ばい」) - トレンド判定
(上昇トレンド/下降トレンド/レンジ) - ボラティリティ判定
(急変動あり/なし) - 売買シグナル
(Buy/Sell/エントリーしない)
👉 メリット
- 結果がシンプルでトレードに直結しやすい
- 評価指標(正解率、F1スコアなど)がわかりやすい
👉 デメリット
- 「横ばい」が多いとクラス不均衡になりやすい
- 微妙な境界(例:小さな値動き)は予測が難しい
回帰学習が向いているケース
回帰は「大きさ」「変化幅」を知りたいときに有効です。
- 価格の変化幅予測
(次の足で +15pips 動く) - ボラティリティ予測
(次の1時間のATR値を予測) - 損切り・利確の幅設定
(利確を20pips、損切りを10pipsにする根拠付け) - 指標後の反応の強さ予測
(何pips動くか?)
👉 メリット
- 数値が直接出るのでリスク・リワード管理に使いやすい
- 「どれくらい伸びるか」を予測できれば大きな武器になる
👉 デメリット
- ノイズに弱く、予測が中央値に寄りやすい
- 実際のトレード精度につなげにくい
難易度の比較
- 分類学習 → 難易度はやや低め
・方向性だけを当てれば良いため学習が安定しやすい。
・ただし「横ばい」などクラスバランス調整が必要。 - 回帰学習 → 難易度は高め
・為替はランダムノイズが多く、数値を正確に当てるのは非常に難しい。
・中央値に寄りやすく「小さな値動きしか当てられない」ことが多い。
WAN
回帰学習の最大の問題は中央値に寄りやすいだね(‘ω’)
イメージとしては短期のMAのような予測結果になるよ
分類学習:安定した学習が可能で、FX初心者に推奨
回帰学習:高度だが実用化には多くの課題あり
実用的な使い分け
実際のAIトレードでは、分類と回帰のハイブリッドが有効です。
- 分類モデルで方向性を決定
→ 「Buy/Sell/Stay」を予測 - 回帰モデルでリスク管理
→ 「どれくらい動きそうか」を予測し、損切り幅・利確幅・ロットを動的に調整
これにより「方向も精度よく」「リスクも適切に」判断できるようになります。
まとめ
- 分類学習 → 「方向性」「状態」の予測に向いている(難易度は低め)
- 回帰学習 → 「数値の大きさ」「変化幅」の予測に向いている(難易度は高め)
- 最適解はハイブリッド
→ 分類で方向を決め、回帰でリスク・リワードを最適化
AIを使ったFX予測では、どちらか片方だけでは限界があります。
分類と回帰を組み合わせて使うことで、より実践的で安定したトレード戦略を構築できるでしょう。