FXのAIモデルを作っていると、
決定木系とディープラーニングでは、特徴量の作り方は何が違うのか?
という疑問を持つ方は多いと思います。
しかし実務でEAを作っていると、
違いは単なる「特徴量設計」だけではなく、
トレード思想そのものが違う
と感じる場面がとても多いです。
結論を先にまとめると、次のように整理できます。
- 決定木系:期待値ベースの正攻法トレード向き
- ディープラーニング:条件一致型・歪み取り(アビトラ的)トレード向き
この記事では、
- 特徴量設計の違い
- 学習のされ方の違い
- トレードロジックとしての性質の違い
という3つの視点から、この差を解説します。
あくまでもWANの考え方です、異論認めます(‘ω’)
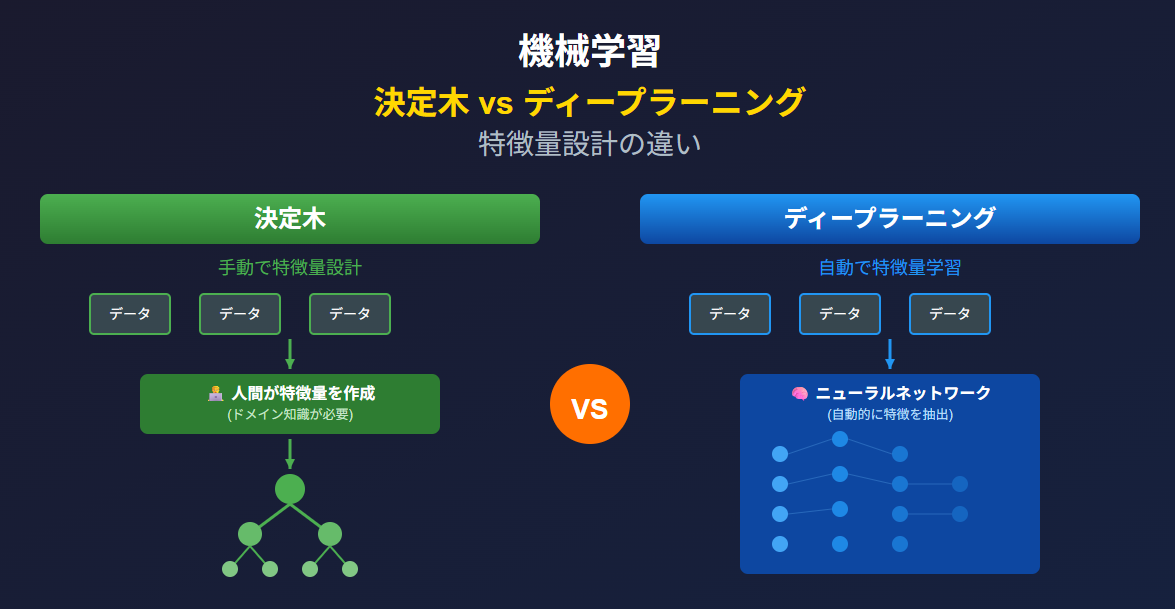
決定木系モデルの考え方(CatBoost / LightGBM など)
決定木系モデルは、入力された特徴量を
- 「この値は〇〇以上か?」
- 「この条件を満たすか?」
という条件分岐の組み合わせで判断します。
そのためモデル自体は
相場の意味を理解しているわけではない
のですが、
人間が相場の見方を特徴量として与える
ことで、トレーダーの思考構造をそのまま学習させることができます。
決定木で重要になる特徴量
FX向けでは、例えば以下のような特徴量が使われます。
- トレンド方向(上位足)
- EMAやVWAPとの乖離
- ATRなどのボラティリティ
- 時間帯(Hour / Minute)
- 他通貨ペアの強弱
これらはすべて、
「この市場状態なら平均すると勝ちやすい」
という期待値の変化を表す指標です。
決定木は、これらの特徴量の組み合わせから
- BUYの方が期待値が高い
- SELLの方が期待値が高い
- そもそもトレードしない方が良い
といった判断を確率的に学習します。
つまり決定木系AIは本質的に、
期待値トレードを機械化したモデル
と言えます。
裁量トレードで行っている
- 環境認識
- 地合い判断
を数値化して統計処理しているイメージに非常に近いです。
ディープラーニングの考え方(CNN / LSTM / Transformer)
一方、ディープラーニングでは設計思想がかなり異なります。
入力としては
- OHLCの時系列
- 複数時間足の価格系列
- ティック近似データ
など、かなり生のデータを使うことが多くなります。
形を覚える学習になりやすい
CNNやAttentionは本質的に
形状パターンの一致度を測る装置
に近い動きをします。
そのため学習の中身は
- このローソクの並び
- この急変後の戻り方
- このブレイク前の形
といった
「この形のとき、次はこうなった」
というパターン記憶になりやすくなります。
この性質から、ディープラーニングは
- 条件が揃った時だけ強い
- それ以外の時間は役に立たない
という挙動になりやすく、
常時エントリー型トレードには不向き
なケースも多いです。
トレードスタイルとしては
市場の一時的な歪みを取る
アービトラージ的な発想
に近い使い方になります。
なぜディープラーニングは壊れやすいのか
FX市場は
- ボラ構造
- 参加者
- アルゴ比率
が時間とともに変化します。
ディープラーニングは
過去に存在した形を前提に学習する
ため、
- 市場構造が変わる
- 同じ形が出なくなる
だけで、優位性が消えることがあります。
バックテストでは強いのに フォワードで急に崩れるEAが多い理由の多くは、
市場の癖を暗記していただけ
というケースです。
もちろん
- 正則化
- データ拡張
- ウォークフォワード
などで耐性は上げられますが、
期待値そのものを学習しているわけではない
という点は本質的に変わりません。
実務で有効なのはハイブリッド構成
実際に長期で使えるEAを作ろうとすると、
- 決定木だけ
- DLだけ
という構成よりも、
複数レイヤーで役割分担させる設計
の方が安定します。
よく使われる構成は次のような形です。
- 決定木:市場状態から期待値方向を判断
- DL:エントリータイミングや局所形状を検出
- ルール:破綻パターンの除外
この構成だと
- 市場が変わっても期待値判断は残り
- 一時的な歪みだけをDLが拾う
という役割分担ができます。
どちらが正しいかではなく、役割が違う
決定木とディープラーニングは、
どちらが優れているか
という話ではありません。
- 決定木:安定した平均利益を積み上げる
- DL:条件が揃った時に大きく取る
という性格の違いがあります。
FXのような非定常市場では、
単一モデルですべてを解決しようとしない
ことの方が重要です。
まとめ
特徴量設計の違いだけでなく、
- 何を学習しているのか
- どんなトレード思想になるのか
という点まで含めると、
- 決定木系:期待値トレードの正攻法
- ディープラーニング:条件一致型・歪み取り型トレード
と考えると、実務では非常に理解しやすくなります。
EA開発では
「どのアルゴリズムを使うか」よりも、
自分はどんな優位性を取りに行っているのか
を先に明確にしてからモデル構成を決める方が、 結果的に安定したシステムを作りやすくなります。
トレードAIは魔法ではなく、
優位性の取り方を機械に任せているだけ
という点を意識して設計することが、 長期運用できるEAへの一番の近道だと思います。
やってることが全然違うから、同じ扱いをすると沼る原因になっちゃう(‘ω’)
オンラインコミュニティ
こちらのコミュニティで、AIや機械学習をトレードに活かすために日々探求しています。
興味のある方は覗いてみてください。