
本記事では、FX取引における革新的な時系列予測モデルであるLSTMとGRUについて解説します。主なポイントは以下の通りです:
- LSTMとGRUの仕組みと特徴の比較
- PythonによるLSTMとGRUモデルの実装方法
- MQL5を用いたFX取引戦略への組み込み手法
- モデルのパフォーマンス評価と最適な選択方法
これらの先進的なモデルを活用し、より洗練されたFX取引戦略の構築を目指しましょう。
最もメジャーな時系列モデルLSTMと、その変種GRUの比較!
再帰型ニューラルネットワークの革新:LSTMとGRUの比較
再帰型ニューラルネットワーク(RNN)は、時系列データの処理に優れた人工知能モデルです。しかし、従来のRNNには長期的な依存関係を学習することが難しいという課題がありました。
この問題を解決するために登場したのが、長短期記憶(LSTM)とゲート付き回帰ユニット(GRU)です。これらの革新的なモデルは、FX取引における時系列予測に新たな可能性をもたらしています。
LSTMの仕組み:長期記憶を実現する革新的アーキテクチャ
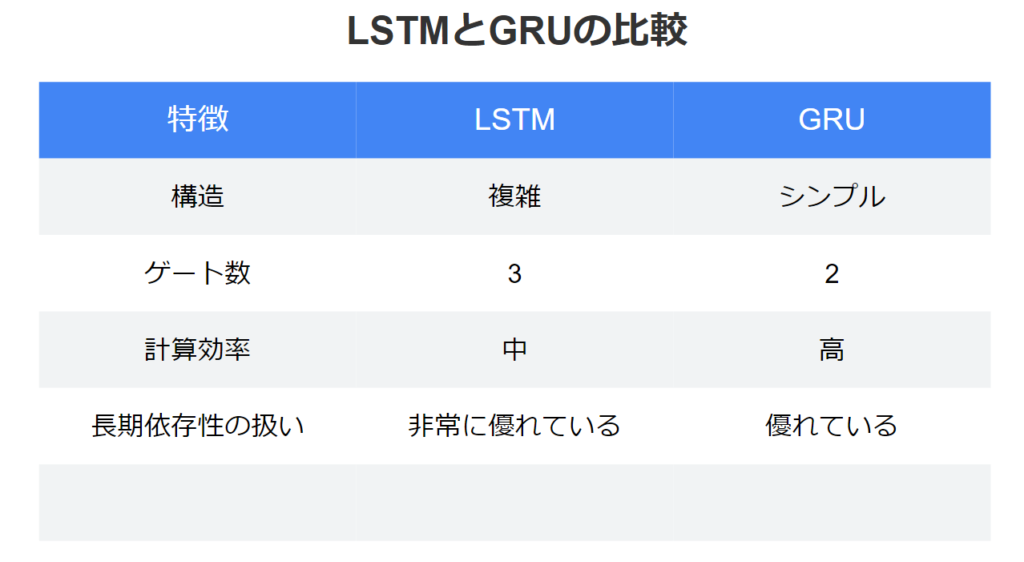
特徴は、長期的な依存関係を効果的に学習できる点にあります。LSTMセルは、通常のRNNユニットよりも複雑な構造を持ち、主に以下の要素で構成されています:
- セル状態:長期的な情報を保持
- 忘却ゲート:不要な情報を削除するか保持するかを決定
- 入力ゲート:新しい情報をセル状態に追加するかどうかを制御
- 出力ゲート:セル状態のどの部分を出力として使用するかを決定
これらの要素が協調して働くことで、LSTMは長期的な依存関係を効果的に学習できます。例えば、数百ステップ前の情報が現在の予測に重要である場合でも、LSTMはその情報を効果的に利用することができます。これは、FX取引のような長期的なトレンドが重要な分野で特に有用です。
GRUの特徴:シンプルながら強力な時系列データ処理
GRUは、2014年にChoらによって提案されたLSTMの変種です。LSTMと同様の性能を持ちながら、より単純な構造を特徴としています。GRUの主な特徴は以下の通りです:
- LSTMのセル状態と隠れ状態を単一の状態に統合
- ゲートの数を3つから2つ(リセットゲートと更新ゲート)に削減
- より単純な構造で効率的な計算を実現
この簡略化されたアーキテクチャにより、GRUはLSTMと同等の性能を維持しつつ、計算効率を向上させています。GRUの単純な構造は、特に小規模なデータセットや計算リソースが限られている環境で有利に働きます。
Pythonで実装するLSTMとGRUモデル

PythonはLSTMとGRUモデルの実装に最適な言語の一つです。TensorFlowやKerasなどの強力なライブラリを使用することで、効率的にモデルを構築できます。これらのライブラリの主な利点は以下の通りです:
- 数行のコードでLSTMやGRUレイヤーを含むモデルを構築可能
- 低レベルの実装詳細を抽象化
- 研究者や開発者がモデルのアーキテクチャに集中可能
例えば、Kerasを使用すると、以下のようなシンプルなコードでLSTMモデルを構築できます:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
model = Sequential([
LSTM(50, activation='relu', input_shape=(time_steps, features)),
Dense(1)
])
model.compile(optimizer='adam', loss='mse')このコードは、50個のユニットを持つLSTMレイヤーと、1つの出力ユニットを持つDenseレイヤーで構成されるモデルを定義しています。
ハイパーパラメータの最適化テクニック
モデルの性能を最大化するには、適切なハイパーパラメータの選択が重要です。効果的な最適化手法には以下のものがあります:
- ランダムサーチ:パラメータ空間からランダムにサンプリングを行い、効率的に広い範囲を探索
- グリッドサーチ:定義された範囲内のすべての組み合わせを試す網羅的な手法
- ベイズ最適化:過去の試行結果を基に次の試行を決定する洗練された手法
def optimize_objective(self, trial):
params = {
"neurons": trial.suggest_int('neurons', 10, 100),
"n_hidden_layers": trial.suggest_int('n_hidden_layers', 1, 5),
"dropout_rate": trial.suggest_float('dropout_rate', 0.1, 0.5),
"learning_rate": trial.suggest_float('learning_rate', 1e-5, 1e-2, log=True),
"hidden_activation_function": trial.suggest_categorical('hidden_activation_function', ['relu', 'tanh', 'sigmoid']),
"loss_function": trial.suggest_categorical('loss_function', ['categorical_crossentropy', 'binary_crossentropy', 'mean_squared_error', 'mean_absolute_error'])
}
val_accuracy = self.build_compile_and_train(params, verbose=0)
return val_accuracy
# optimize for 50 trials by default
def optimize(self, n_trials=50):
study = optuna.create_study(direction='maximize')
study.optimize(self.optimize_objective, n_trials=n_trials)
return study.best_paramsこれらの手法を使用することで、モデルの性能を大幅に向上させることができます。
AIといっても予測精度の向上には無限の可能性があるんだ(‘Д’)
特徴量の重要度分析:SHAPの活用
SHAPライブラリを使用することで、モデルの各特徴量が予測に与える影響を可視化し、理解することができます。これは、モデルの解釈可能性を高め、取引戦略の改善に役立ちます。
FX取引では、SHAPを使用することで、どの市場指標や経済指標が予測に最も影響を与えているかを特定し、それに基づいて取引戦略を調整することができます。
def check_feature_importance(self, feature_names):
# Sample a subset of training data for SHAP explainer
sampled_idx = np.random.choice(len(self.x_train), size=100, replace=False)
explainer = shap.KernelExplainer(self._rnn_predict, self.x_train[sampled_idx].reshape(100, -1))
# Get SHAP values for the test set
shap_values = explainer.shap_values(self.x_test[:100].reshape(100, -1), nsamples=100)
# Update feature names for SHAP
feature_names = [f'{feature}_t{t}' for t in range(self.time_step) for feature in feature_names]
# Plot the SHAP values
shap.summary_plot(shap_values, self.x_test[:100].reshape(100, -1), feature_names=feature_names, max_display=len(feature_names), show=False)
# Adjust layout and set figure size
plt.subplots_adjust(left=0.12, bottom=0.1, right=0.9, top=0.9)
plt.gcf().set_size_inches(7.5, 14)
plt.tight_layout()
# Get the class name of the current instance
class_name = self.__class__.__name__
# Create the file name using the class name
file_name = f"{class_name.lower()}_feature_importance.png"
plt.savefig(file_name)
plt.show()MQL5での活用:LSTMとGRUを用いたFX取引戦略の構築

PythonでトレーニングしたLSTMやGRUモデルをMQL5で活用することで、高度なシステムを構築できます。この統合を実現するための重要な要素は以下の通りです:
ONNXフォーマットを利用したモデルの移植
ONNXは、Open Neural Network Exchangeの略で、異なる機械学習フレームワーク間でモデルを交換するための開放型標準です。
PythonでトレーニングしたLSTMやGRUモデルをONNXフォーマットに変換し、MQL5で読み込むことで、MetaTrader 5プラットフォーム上で直接モデルの予測を活用できます。
def save_onnx_model(self, onnx_file_name):
# Convert the Keras model to ONNX
spec = (tf.TensorSpec((None, self.time_step, self.x_train.shape[2]), tf.float16, name="input"),)
self.model.output_names = ['outputs']
onnx_model, _ = tf2onnx.convert.from_keras(self.model, input_signature=spec, opset=13)
# Save the ONNX model to a file
with open(onnx_file_name, "wb") as f:
f.write(onnx_model.SerializeToString())
# Save the mean and scale parameters to binary files
scaler.mean_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_mean.bin")
scaler.scale_.tofile(f"{onnx_file_name.replace('.onnx','')}.standard_scaler_scale.bin")予測精度の評価:テストデータでの検証
LSTMとGRUモデルの予測精度を評価する際の重要なポイント:
- 【テストデータの使用】訓練に使用していない独立したデータセットで評価 。モデルの汎化性能を正確に測定
- 【両モデルの一般的な特徴】LSTMとGRU共に高い精度を示す傾向。データセットの特性により性能に差が出る場合がある
- 【LSTMの強み】長期的な依存関係が重要なデータセットでより優れた性能。複雑な時系列パターンの捕捉に適している
- 【GRUの強み】短期的な予測タスクで効率的に機能。比較的単純なデータセットや限られたデータ量での学習に適している
- 【評価の際の考慮点】予測の時間スケール(短期・中期・長期)。データの複雑さと長期依存性の程度。計算効率とモデルの複雑さのトレードオフ
この評価を通じて、特定のFX取引に最適なモデルを選択することができます。
取引パフォーマンス:利益率と勝率の分析
実際の取引シミュレーションを通じて、LSTMとGRUベースのEAの取引パフォーマンスを比較します。以下の指標を分析し、各モデルの実用性を評価します:
- 利益率
- 勝率
- 最大ドローダウン
- シャープレシオ
これらの指標を総合的に分析することで、各モデルの実際の取引環境における効果を評価できます。
計算効率とリソース使用量の比較
LSTMとGRUの計算効率とリソース使用量を比較します。GRUは一般的にLSTMよりも計算効率が高いため、リアルタイム取引やリソースが制限された環境では有利な場合があります。
一方、LSTMはより複雑なパターンを学習できる可能性があるため、十分な計算リソースがある場合には優れた性能を発揮する可能性があります。
選択の指針:あなたの取引戦略に最適なモデルは?
LSTMとGRUのどちらを選択するかは、取引戦略や環境に応じて慎重に検討する必要があります。以下の要素を考慮して、最適なモデルを選択しましょう:
データの特性と予測期間による選択
- 短期的な予測:シンプルで高速なGRUが適している場合が多い
- 長期的な市場トレンド予測:より複雑な依存関係を学習できるLSTMが適している可能性がある
- データの複雑さ:より複雑なデータセットではLSTMが優位な場合がある
計算リソースとトレードオフ
- 限られた計算リソース:GRUの効率性を活用
- 高性能ハードウェア利用可能:LSTMの複雑なモデリング能力を最大限に活用
まとめ
LSTMとGRUは、FX取引における時系列予測に革新的なアプローチをもたらす強力なツールです。これらのモデルを適切に実装し、最適化することで、より洗練された取引戦略を構築し、市場の動きをより深く理解することができます。
これらのモデルを使用する際は、以下の点に注意する必要があります:
- 過学習のリスク:モデルが訓練データに過度に適合し、新しいデータに対する汎化性能が低下する可能性
- 市場の急激な変化への対応:予期せぬイベントや急激な市場変動に対するモデルの脆弱性
- 継続的なモニタリングと適応の必要性:市場条件の変化に応じたモデルの再訓練や調整
これらの課題に適切に対処することで、LSTMやGRUを活用した取引戦略は、FX市場で優位性を獲得する強力なツールとなる可能性があります。
超重要な記事だから、本家記事も絶対見てね!
オンラインコミュニティ
こちらのコミュニティで、AIや機械学習をトレードに活かすために日々探求しています。
興味のある方は覗いてみてください。
参考記事
