 AI
AI 【MinaraAI】話題のAI金融サービスで「一番重要なポイント」
最近、Xで話題になっているAI金融サービス「MinaraAI」。「AIが代わりに資産運用してくれる」と聞くと、とても魅力的に感じますよね✨ですが、お金が関わるサービスほど大切なのは 仕組みを理解すること です。この記事では、初心者の方が見落...
AI 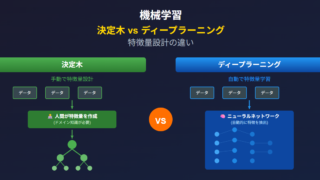 AI
AI  AI
AI 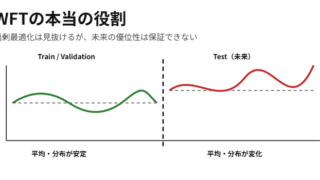 AI
AI  AI
AI  AI
AI  AI
AI  AI
AI  AI
AI  AI
AI