 機械学習
機械学習 【機械学習】CNN-LSTMを天気予測を例に解説(時系列分析モデル)
CNN-LSTMとは何かを初心者向けに解説。天気予測を例に、CNNとLSTMの役割、シーケンス長や特徴量など時系列データ分析の基本をわかりやすく説明します。
機械学習  MQL5記事
MQL5記事  AI
AI 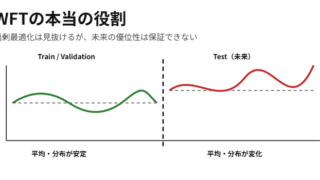 AI
AI  AI
AI  AI
AI  AI
AI  AI
AI  AI
AI 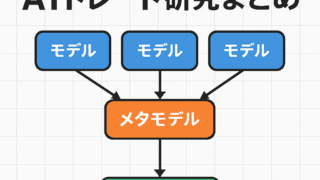 AI
AI